Adapting the proposal distribution¶
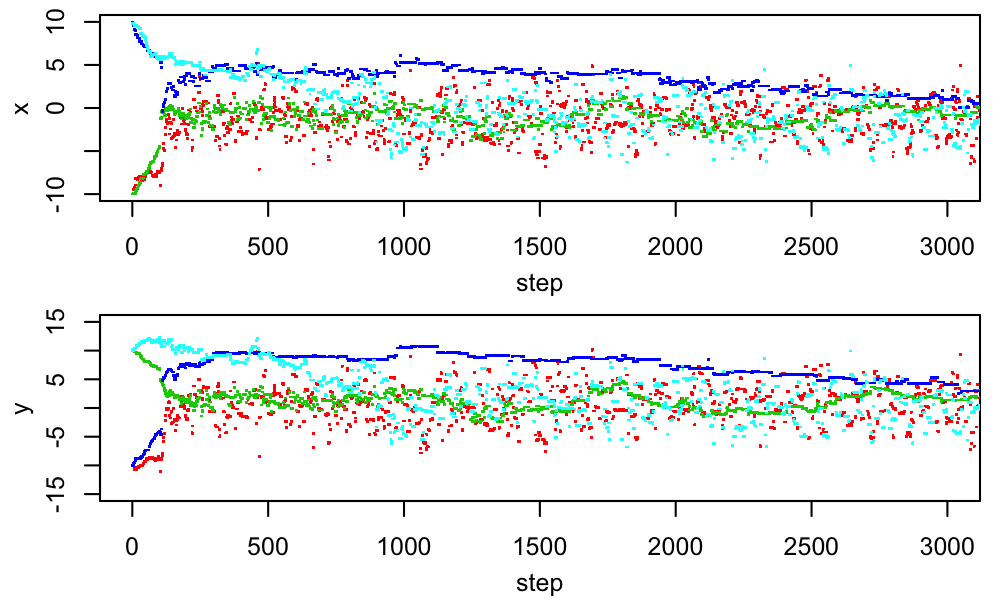
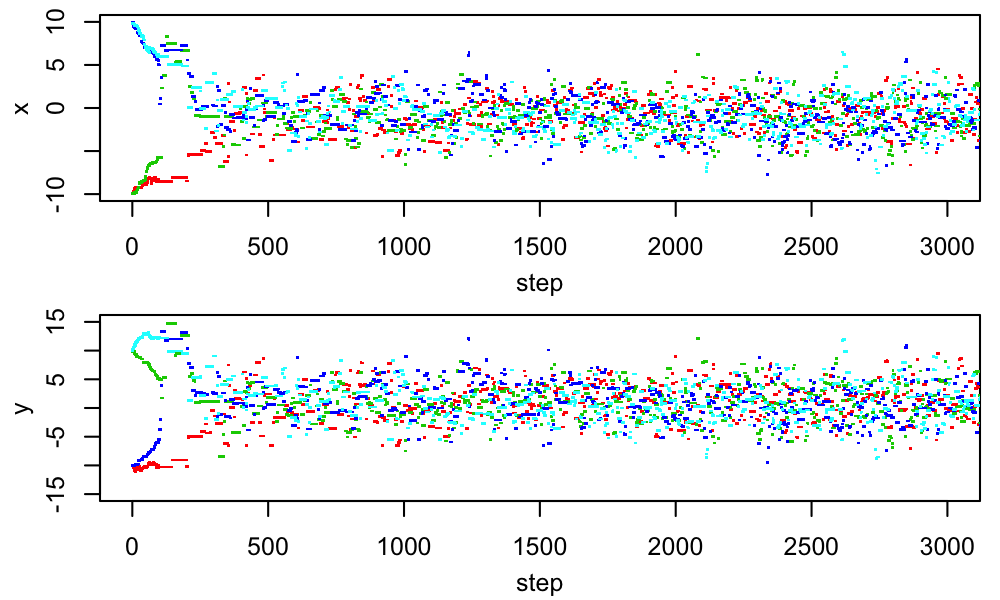
One way of making the proposal distribution more efficient would be to customize the proposal scale for each parameter. If we believe the chain has begun (laboriously) to sample from the posterior, we could periodically compute the standard deviation of the samples so far in each direction, and use that as a guess of the appropriate proposal scale. More generally, we could look at the multidimensional covariance of the samples so far, and adjust the shape of our proposal distribution to match; this would let us learn about and compensate for parameter degeneracies. This change is equivalent to using a rotated coordinate basis, with appropriate scales in each new basis direction, for our proposal distribution. We could visualize it like this:
Original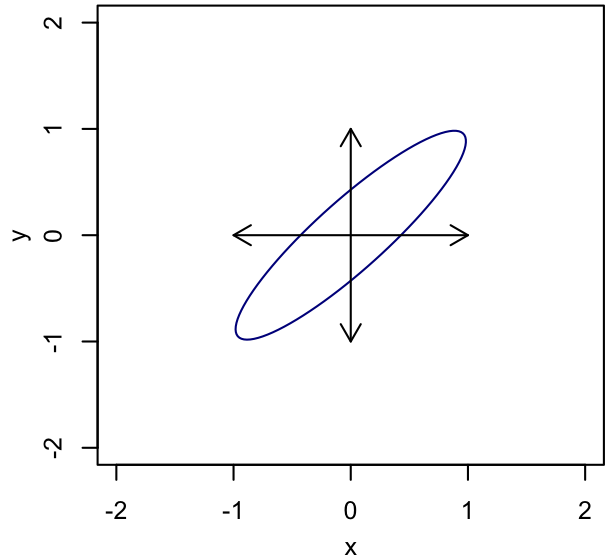 |
Proposal basis change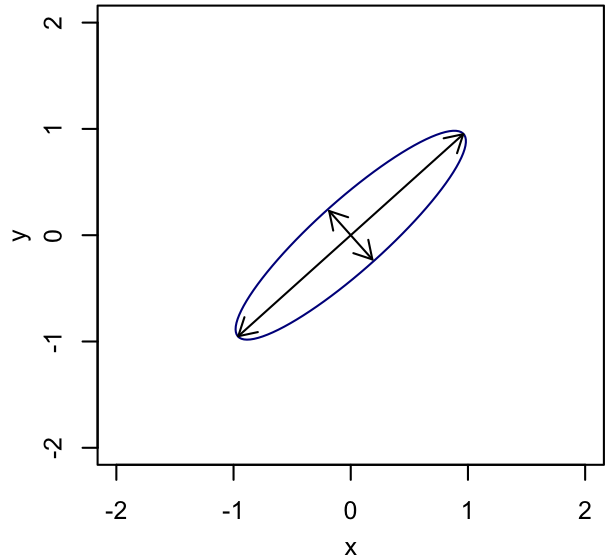 |
Parameter basis change |
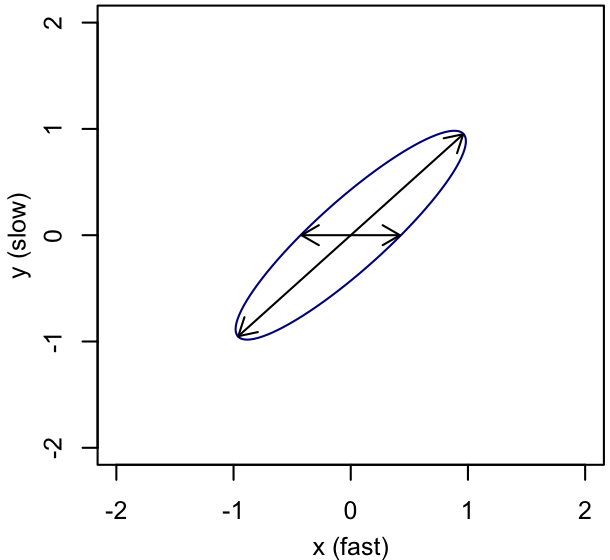
In each panel, the ellipse shows the shape of the posterior distribution, and the vectors show the coordinate basis with respect to which the proposal distribution is defined. (We are not confined to proposing along these directions, but are imagining that we want the proposal distribution to be simple with respect to this basis, and have a proposal scale associated with each basis direction.) On the left, the basis is Cartesian, with the scales set to the standard deviation of the (marginal) posterior in each direction; we can see that this results in proposals that are too large on average to be accepted often. In the center, we have rotated the basis for proposals to align with the major and minor axes of the iso-probability surfaces, and tuned the associated scales appropriately. This can equivalently be accomplished by re-defining the parameters to reduce the correlation of the PDF, as illustrated on the right. (Note that, being a rotation and scaling, this parameter transformation is linear, meaning that the priors are invariant under it. If we had used a nonlinear reparametrization, we'd need to worry about transforming the prior density accordingly.) For a nice, elliptical PDF like the one shown, a basis that diagonalizes the covariance matrix is optimal.