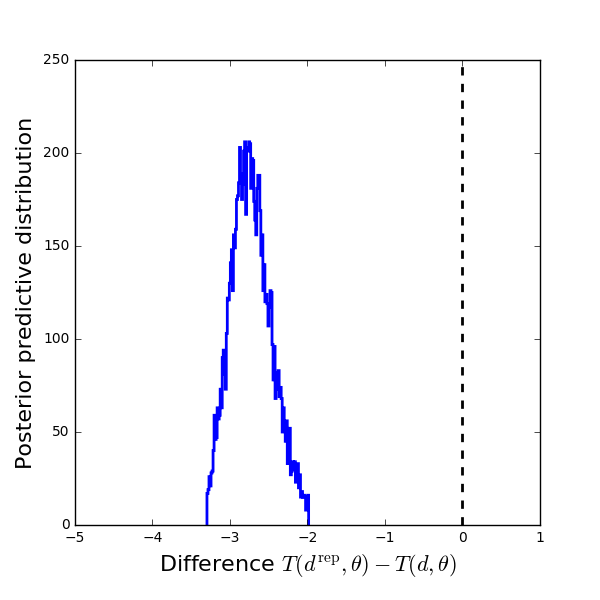
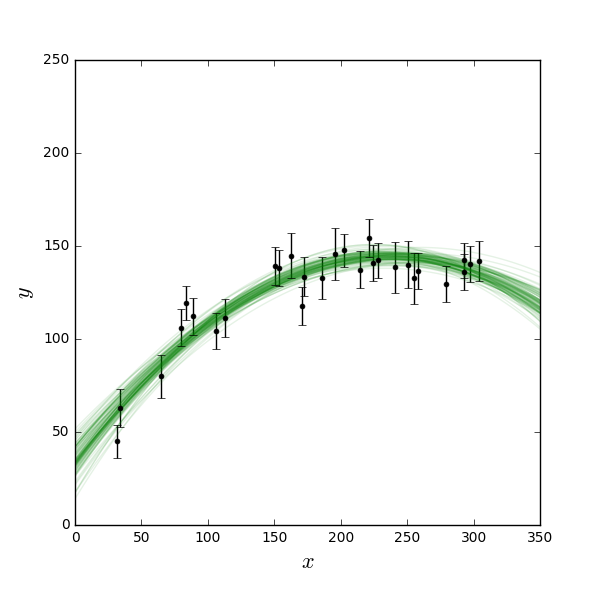
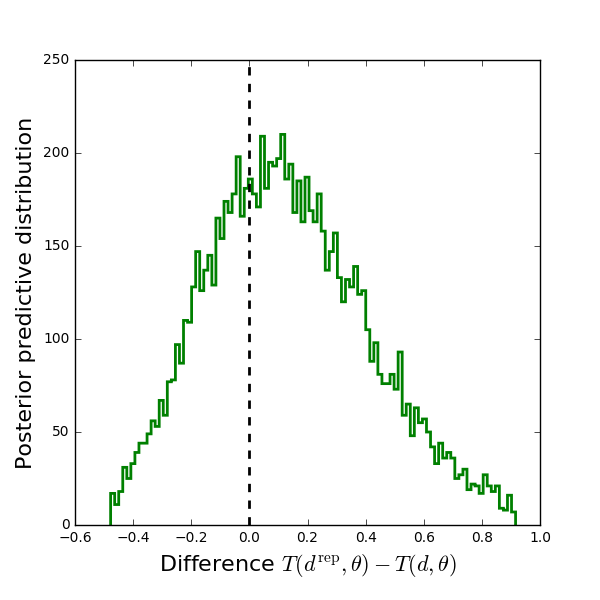
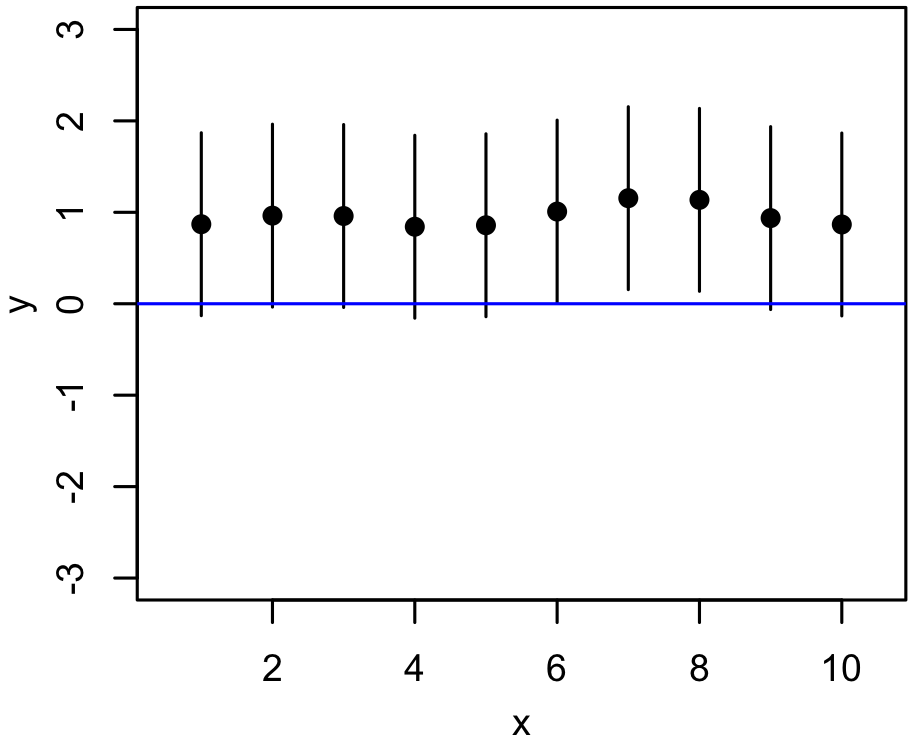
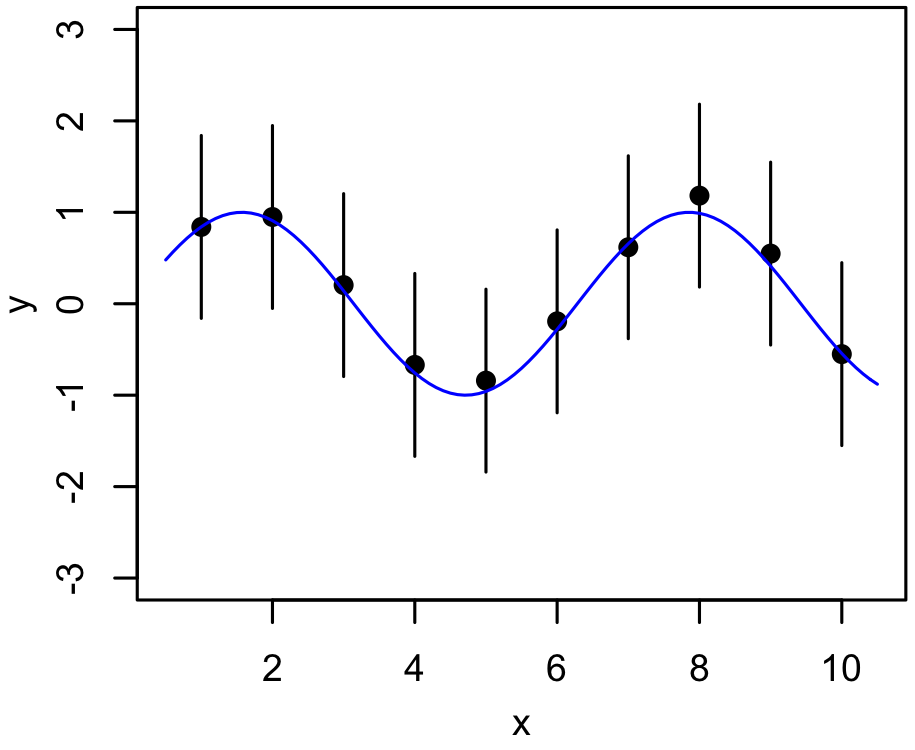
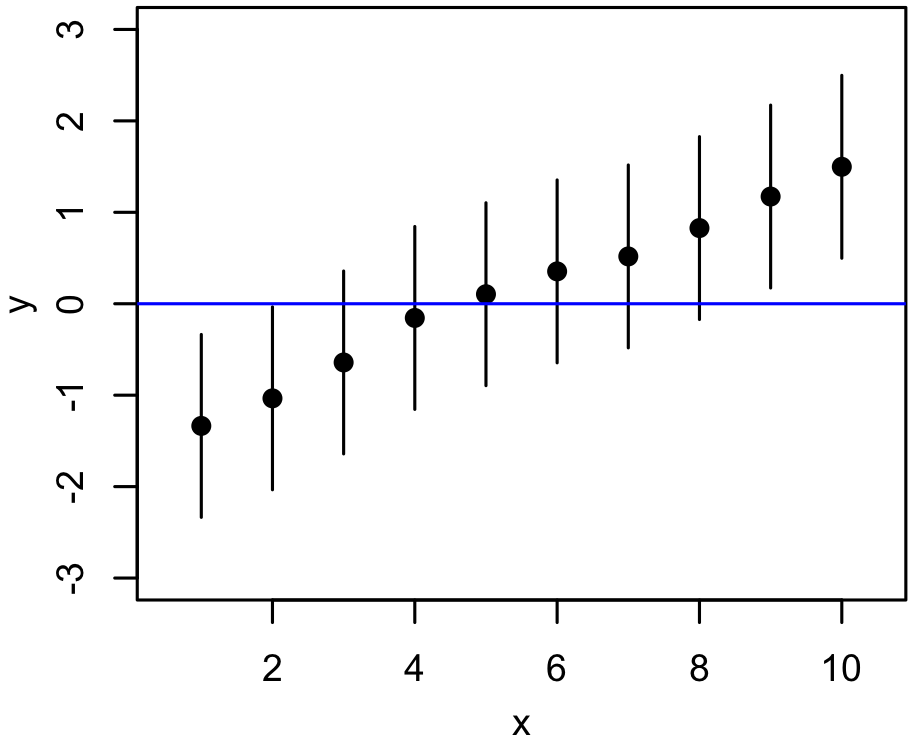
Bayesian Model Comparison¶
What about the third model evaluation question: How probable are our competing models in the light of the data? This question cannot be asked in classical statistics, where only data have probability distributions. However, Bayes theorem gives us a framework for assessing relative model probabilities that naturally includes Occam's razor.
Recall that we can write Bayes' Law for inference on parameters $\theta$ given a model $H$ and data $D$ as
$P(\theta|D,H)=\frac{P(D|\theta,H)P(\theta|H)}{P(D|H)}$.
Analogously, we can do inference on models within some space of possible models, $\Omega$;
$P(H|D,\Omega)=\frac{P(D|H,\Omega)P(H|\Omega)}{P(D|\Omega)}$.
Again, remember that $H$ includes all aspects of specifying the model, including our prior PDF assignments. Everything here has a straightforward analogy to the parameter inference that you're familiar with, so
- $P(H)$ is a prior probability over models;
- $P(D|H)=\int P(D|\theta,H) \, p(\theta|H) \, d\theta$ is the evidence, which previously appeared in the denominator for parameter inference but now takes on the role that the sampling distribution had; and
- $P(D|\Omega)$ is a new normalizing factor, which we will normally ignore (just as we didn't worry about the evidence when doing only parameter inference).
To compare models within the space $\Omega$, we would look at the ratio of their posterior probabilities,
$\frac{P(H_2|D)}{P(H_1|D)}=\frac{P(D|H_2)\,P(H_2)}{P(D|H_1)\,P(H_1)}$.
which simply requires us to
- assign meaningful priors to models,
- assign meaningful priors to parameters, and
- calculate the evidence integral.
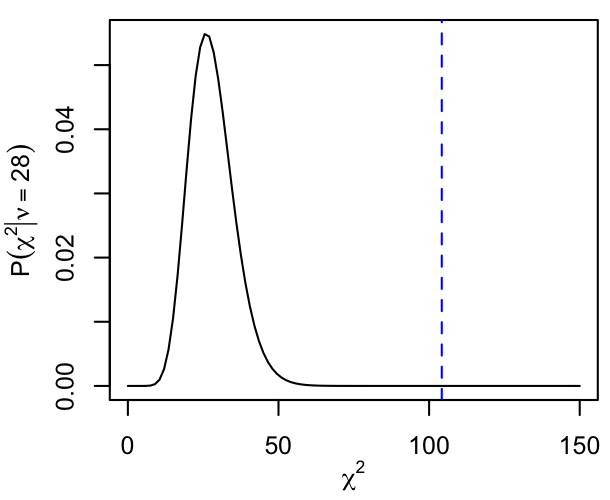
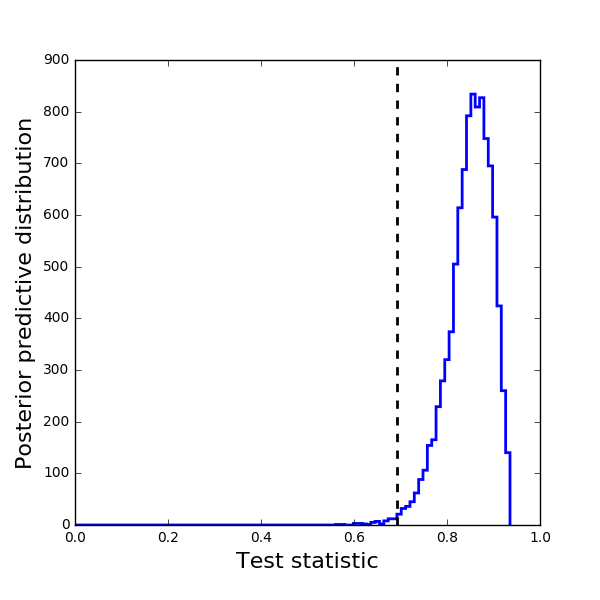
The Bayesian approach is qualitatively different from other model assessments discussed above. While they focused primarily on prediction accuracy, here we simply apply Bayes' Law at the level of the model as a whole, with the evidence updating our prior knowledge into a posterior probability. There are no inherent mathematical limitations to this procedure, in contrast to various other hypothesis tests that are only valid under certain assumptions (such as the models being nested, e.g. the classical $F$ test for comparing $\chi^2$ values). Any two models, no matter how fundamentally different, can be compared with this technique.