Convergence tests¶
Note that both of the checks below rely on having multiple, independently run chains, ideally started in very different parts of parameter space. This is a good idea in any case, and multiple chains that do converge can be merged (after removing the burn-in phase from each; see below) before we draw conclusions from them.
Visual inspection¶
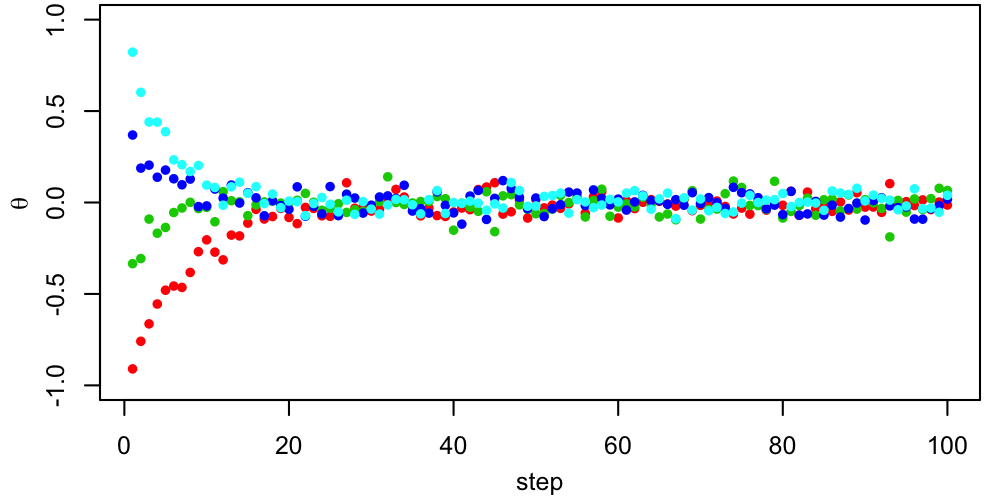
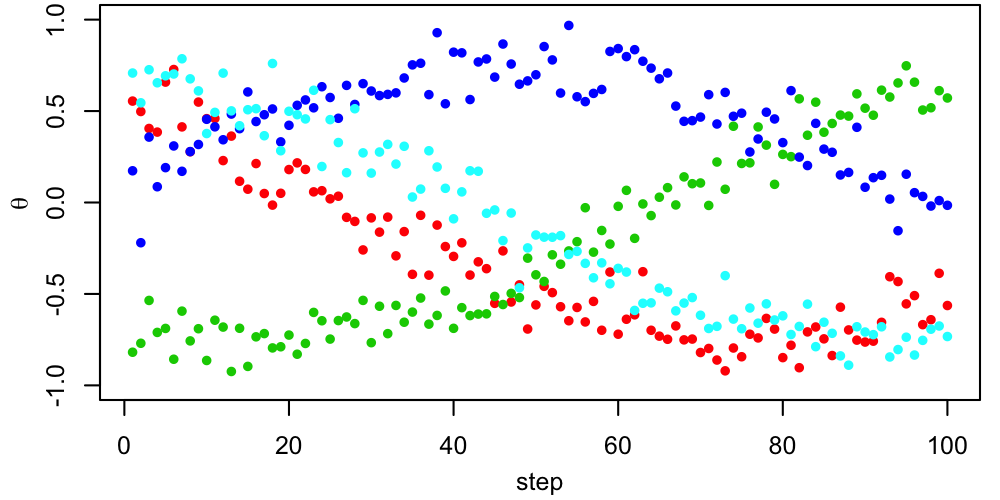
Below, we can see 4 Metropolis chains (different colors) with different starting points exploring a 2-dimensional parameter space.
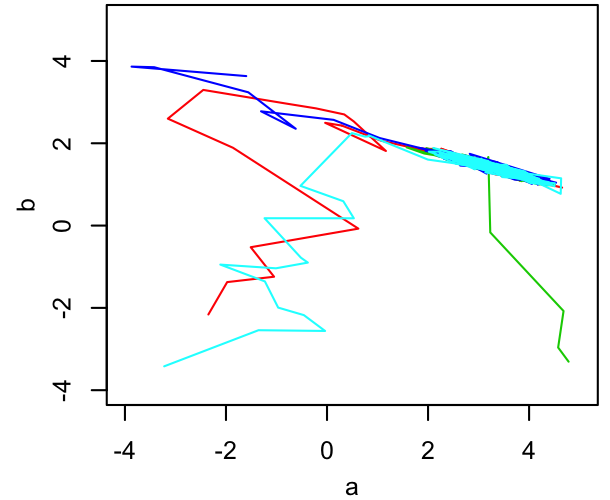 |
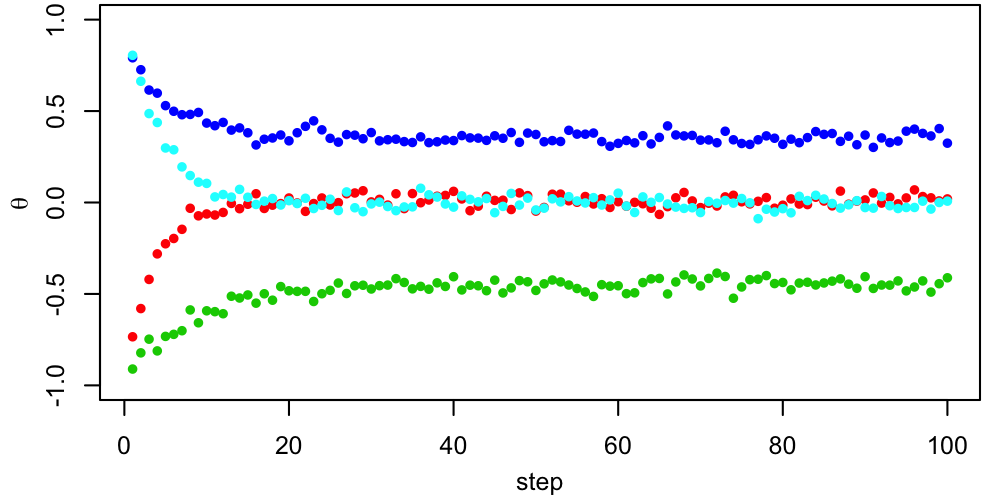
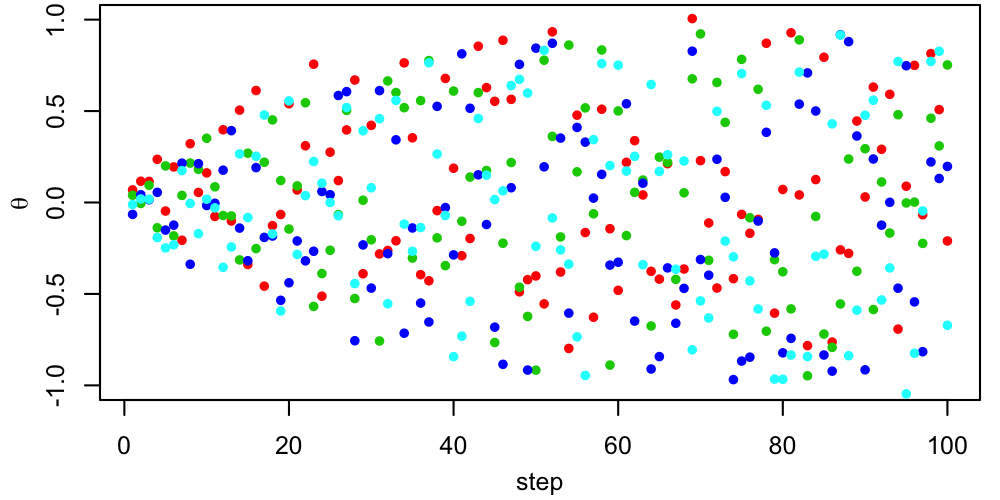
A 2D figure like this can be useful for verifying that the chains all end up in the same place, but in many dimensions it isn't really practical. More often, we would look at trace plots of each parameter, showing its value as a function of step number.
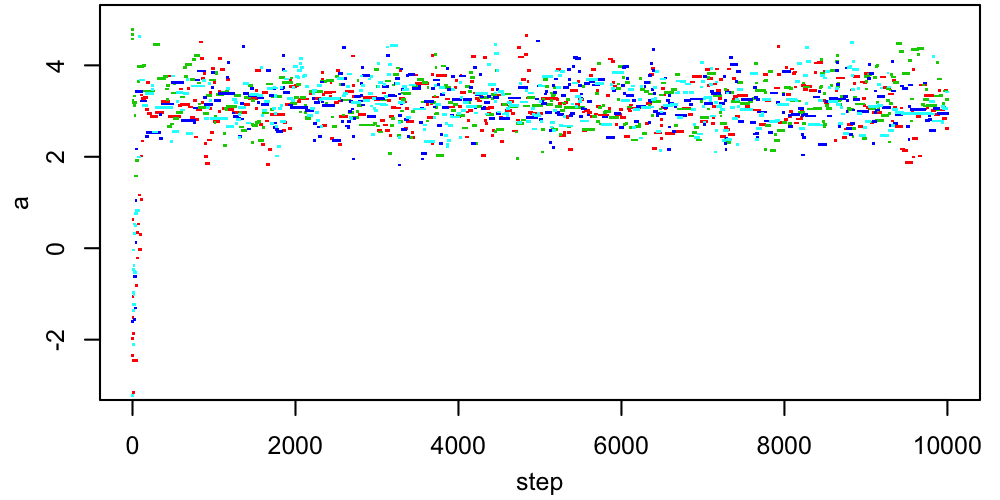 |
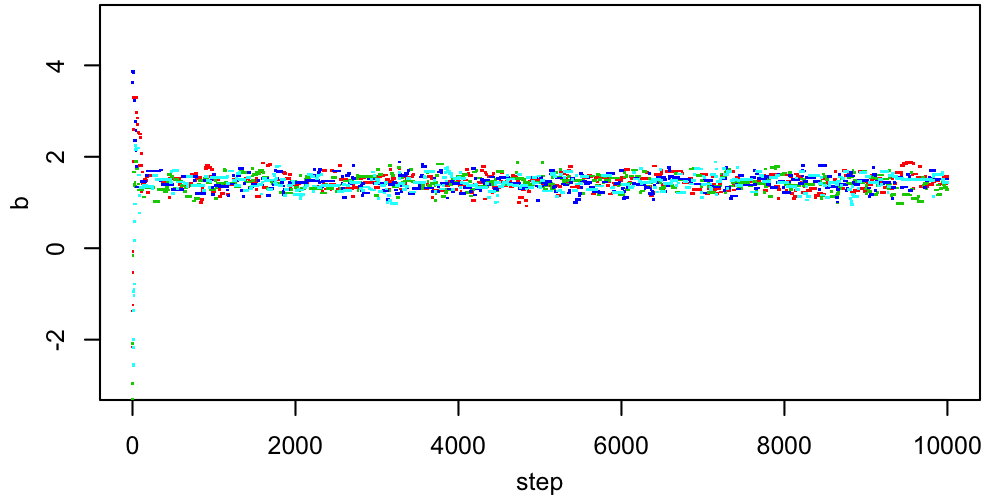 |
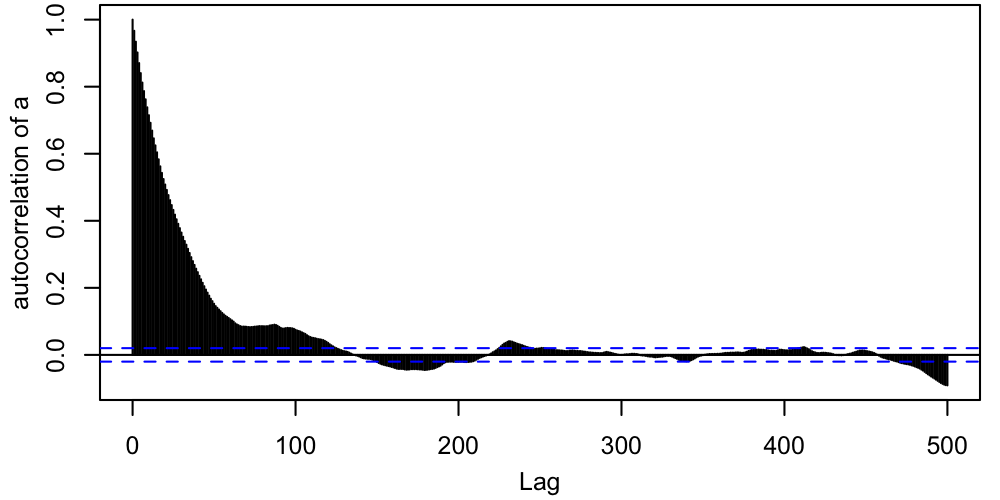
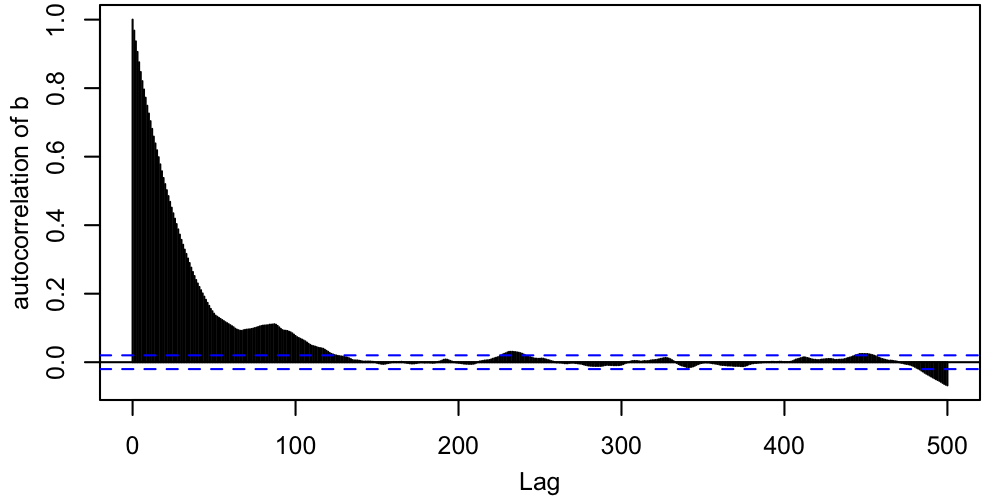
The questions to ask ourselves, based on these traces, are
- How stationary does each sequence appear?
- Do all chains look like they're sampling the same PDF?
Remember that "stationary" doesn't mean that the chain must be staying in exactly the same place. Rather, it means that one part of the chain (e.g. steps 2000-3000) should statistically resemble other parts (e.g. steps 6000-7000).
In this case, things look pretty good, apart from the early behavior corresponding to the period just after each chain is started when it's finding its way to the region where the target PDF is non-tiny. This early behavior is called burn-in, and standard practice is to remove it from the chains before computing summaries like credible intervals. In this case, we might conservatively through away the first $\sim500$ steps from each chain. After this period, the chains are mixing well (all jumbled up). This "confetti projectile vomit" appearance is what we're looking for.$^1$