Notes: Bayes' Law¶
In which we will
- see how the concept of a generative model and our background in the calculus of probability allow us to infer properties of a model from data
- work through a simple example of Bayesian inference
- think about prior distributions
# get a bunch of imports out of the way
import matplotlib.pyplot as plt
plt.rc('text', usetex=True)
plt.rcParams['xtick.labelsize'] = 'x-large'
plt.rcParams['ytick.labelsize'] = 'x-large'
import numpy as np
import scipy.stats as st
%matplotlib inline
Bayesian inference¶
You've seen in the generative models notes how writing down a model with enough specificity that we could produce mock data is equivalent to writing down a joint probability distribution for all the models parameters and the resulting data. Let's abbreviate this as
$P(\mathrm{params},\mathrm{data}|\mathrm{model})$.
Here I've explicitly conditioned on a choice of model, with any assumptions that come along with it. Much of the time this doesn't need to be explicitly written, e.g if the choice of model is not really in question and we're only interested in constraining the values of the parameters ("params") of the model, which is our most common use case. But, for now, let's leave the "model" there.
Using the definition of conditional probability, we can immediately expand this as
$P(\mathrm{params},\mathrm{data}|\mathrm{model}) = P(\mathrm{params}|\mathrm{model})\,P(\mathrm{data}|\mathrm{params},\mathrm{model}) = P(\mathrm{data}|\mathrm{model})\,P(\mathrm{params}|\mathrm{data},\mathrm{model})$,
and, through the power of division, conclude that
$P(\mathrm{params}|\mathrm{data},\mathrm{model}) = \frac{P(\mathrm{params}|\mathrm{model})\,P(\mathrm{data}|\mathrm{params},\mathrm{model})}{P(\mathrm{data}|\mathrm{model})}$
In this form, the expression is known as Bayes' Law. Note that the numerator of the RHS is the factorization of the joint probability that our generative models encode.
Aside¶
Bayes' Law is also frequently referred to as Bayes' Theorem or Bayes' Rule. One could argue that "theorem" is inappropriate, since a theorem is a statement that has been mathematically proven, whereas all we did was apply one of the axioms of probability. Of course, this apparent simplicity is due to several hundred years of development of probability as a branch of mathematics (including said axioms and the definition of conditioning). In any case, the importance of Bayes' Law is not in the impressiveness of its derivation, but in the insight that the formal language of probability is the natural (and correct) way to describe the knowledge we acquire from data.
It's also worth noting that, like many equations that have a name attached to them, Bayes' Law was neither fully appreciated by nor uniquely discovered by Bayes. He was apparently the first to write it down, though he didn't really do anything with it or even publish the derivation (it was published posthumously). Later, and independently, Laplace developed and applied the approach that we now call Bayesian analysis. Of course, a number of others contributed along the way to our modern formalism (Jeffreys, Cox and Jaynes being probably the most salient names).
Anyway, we'll call the law "Bayes" because everyone else does.
Components of Bayes' Law¶
The above equation hopefully makes sense, at least as a mathematical abstraction. It will take time to gain intuition as to what it actually means, but we can start with the interpretation of each factor.
The prior distribution¶
$P(\mathrm{params}|\mathrm{model})$ appears to be the marginal distribution of our model parameters, irrespective of the data. We interpret this to be a probability distribution encoding what we know about the parameters before accounting for the information gained from the data, hence the name "prior" distribution. We saw this quantity already in the generative model context where, correctly, it had no dependence on the data (since choosing parameter values is the first step of the generative process that ends with producing mock data).
Exactly what this distribution should be will vary on a case by case basis, but it's usually best to think of the choice of prior as part of the specification of the model (or, alternatively, of the problem you're trying to solve). We'll return to this later.
The sampling distribution¶
$P(\mathrm{data}|\mathrm{params},\mathrm{model})$ we have also seen in the generative context - this is the probability of a particular set of parameter values producing a given data set. The name "sampling distribution" makes sense if we think of our data as samples from a larger set of possible measurements, an analogy that works better for sociology or games of chance than for astronomy.
Recall that, in inference, our data are constants and the parameter values are unknown. It's natural, therefore, to think about the sampling distribution as a function of model parameters, with the data fixed. In classical statistics, this is exactly what's known as the likelihood function, and we will inevitably be sloppy and use use that terminology interchangeably with "sampling distribution".
However, don't fall into the trap of thinking that the sampling distribution is normalized over the space of parameter values - it isn't. For a given set of fixed parameter values, it's normalized over the space of possible data sets.
The evidence¶
The normalizing constant on the RHS of Bayes' Law, $P(\mathrm{data}|\mathrm{model})$, is called the evidence. Mathematically, it is the marginal probability of the observed data, or equivalently
$P(\mathrm{data}|\mathrm{model}) = \int d(\mathrm{params}) \, P(\mathrm{params}|\mathrm{model}) \, P(\mathrm{data}|\mathrm{params},\mathrm{model})$.
In the circumstances where we're only interested in learning about the model parameters, having already chosen a model, we won't normally need to evaluate the evidence (we'll see why later on). It's utility arises in the context of choosing among competing models. To do so we would need to apply Bayes' law again, having already marginalized over the parameters of the competing models:
$P(\mathrm{model}|\mathrm{data}) = \frac{P(\mathrm{model})\,P(\mathrm{data}|\mathrm{model})}{P(\mathrm{data})}$.
In this meta-invocation of Bayes' Law, the evidence plays the role of the sampling distribution/likelihood, and we correspondingly have prior and posterior distributions over possible models. (There is also a new normalizing constant, $P(\mathrm{data})$, marginalized over possible models ... which we normally will not need to evaluate.)
To begin with, we'll focus on the task of using data to constrain the parameters of a given model, so if the above was confusing you can safely forget about the evidence for a little while.
The posterior distribution¶
$P(\mathrm{params}|\mathrm{data},\mathrm{model})$ is a distribution over parameter values encoding what we know about the parameters after accounting for the information in the data. The is the end result of our inference - a function telling us the relative probability of different parameter values in light of the gathered data.
Example: does a positive test mean positive?¶
This example is ostensibly not astrophysical, but it's the example generally used to first demonstrate how Bayesian inference works.
Imagine you're being screened for an uncommon disease or condition using a test that is known to produce false positives only 1% of the time and false negatives only 0.01% of the time, and your test is positive. A false positive rate of 1% means that 99% of test's positive results are correct and only 1% of them are incorrect, so you're probably sick, right?
The answer is it depends. The test result alone is not enough information for us to draw a conclusion. Let's set up the inference problem.
First, because we absorbed the pointed lessons from the Generative Models notes, we will carefully define a model to explain the data. In this case, it might be very simple, consisting of the parameters:
- $\theta$: a variable encoding whether we are sick (1) or well (0),
- $r_\mathrm{fp}$: the false positive rate of the test, which we are given as 0.01,
- $r_\mathrm{fn}$: the false negative rate of the test, which we are given as 0.0001, and
- $T$: the outcome of the test, also a Bernoulli variable encoding positive (1) or negative (0), and data.
The PGM could be sketched like this:
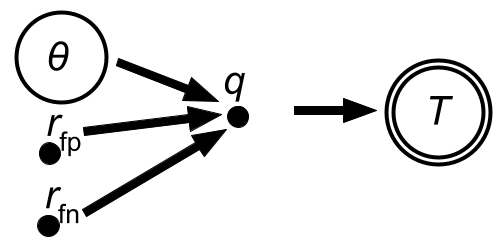 |
And the model expressed as:
- $\theta \sim$ Bernoulli prior
- $r_\mathrm{fp} = 0.01$
- $r_\mathrm{fn} = 0.0001$
- $q = \theta(1-r_\mathrm{fn}) + (1-\theta)r_\mathrm{fp}$
- $T \sim \mathrm{Bernoulli}(q)$
Here I've introduced the intermediate quantity $q$, the probability of the test returning positive, which is equal to $(1-r_\mathrm{fn})$ if you are actually sick and $r_\mathrm{fp}$ if not. Note that $\theta$ is defined as 1 or 0, depending on whether we're sick or not, not as the probability that we're sick. The latter we will just call $P(\theta=1)$, which specifies a Bernoulli prior for $\theta$ (the only distribution that makes sense in this case).
Next, given that my data is $T=1$ we can write down the sampling distribution:
$P(T=1|\theta) = q(\theta,r_\mathrm{fp},r_\mathrm{fn}) = \theta(1-r_\mathrm{fn}) + (1-\theta)r_\mathrm{fp}$.
Finally, we can write down the posterior for $\theta$:
$P(\theta|T=1) = \frac{P(\theta)P(T=1|\theta)}{P(T=1)} = \frac{P(\theta)P(T=1|\theta)}{P(\theta=0)P(T=1|\theta=0) + P(\theta=1)P(T=1|\theta=1)}$.
Ok... that's a whole lot of equations, and we still don't have an answer. In particular, the expression above depends on the prior, $P(\theta)$, and we still haven't said what that is. And that's the point - to draw a conclusion from the test, we need to know the a priori probability that you were sick, not just the test outcome itself. And this information wasn't even really given in the description of the problem. Quite simply, we have no business drawing a conclusion from the test unless we can specify the model further.
Consider the scenario where this test is routinely given to everyone once they reach a certain age. Then $P(\theta)$ would be the prevalence of this disease in the whole population (at that age), which is knowable. For the purposes of the example, we might have $P(\theta=1) = 10^{-5}$, or something similarly small. Now we have enough information to work out the posterior for $\theta$. Let's do so, following the model pseudo-code above.
P_theta1 = 1e-5
r_fp = 0.01
r_fn = 0.0001
def q(theta):
return theta*(1.0-r_fn) + (1.0-theta)*r_fp
# unnormalized posterior (numerator of Bayes' Law rhs)
unp0 = (1.0 - P_theta1) * q(0.0) # proportional to P(theta=0|T=1)
unp1 = P_theta1 * q(1.0) # proportional to P(theta=1|T=1)
# normalize the posterior
evidence = unp0 + unp1
post0 = unp0 / evidence
post1 = unp1 / evidence
print("posterior:\n P(theta=0|T=1) =", post0)
print(" P(theta=1|T=1) =", post1)
print("\nevidence:\n P(T=1) =", evidence)
posterior: P(theta=0|T=1) = 0.9990010888221749 P(theta=1|T=1) = 0.000998911177825071 evidence: P(T=1) = 0.010009899000000001
We can see that, in this case, the odds are very much against illness even with a positive test.
On the other hand, consider a scenario where the rate of illness in the population is much higher, say 1%. Alternatively, you could imagine that the test is not a routine screening, but one a doctor recommended based on some reported symptoms - then we should condition everything in the problem on those symptoms, and the conditional prior $P(\theta=1|\mathrm{symptoms})$ could be much higher than the marginal $P(\theta=1)$. Either way, let's repeat the calculation for that case:
P_theta1 = 1e-2
# unnormalized posterior (numerator of Bayes' Law rhs)
unp0 = (1.0 - P_theta1) * q(0.0) # proportional to P(theta=0|T=1)
unp1 = P_theta1 * q(1.0) # proportional to P(theta=1|T=1)
# normalize the posterior
evidence = unp0 + unp1
post0 = unp0 / evidence
post1 = unp1 / evidence
print("posterior:\n P(theta=0|T=1) =", post0)
print(" P(theta=1|T=1) =", post1)
print("\nevidence:\n P(T=1) =", evidence)
posterior: P(theta=0|T=1) = 0.49751243781094534 P(theta=1|T=1) = 0.5024875621890548 evidence: P(T=1) = 0.019899
Now, for the same test and outcome, the probability of illness has jumped to 50-50! Bottom line: we have to specify a model fully and work out the posterior distribution to draw conclusions from the test, rather than trying to intuit something from the test alone.
Note that the evidence, $P(T=1)$, was fairly small in both cases. That is, the probability of getting our data, irrespective of whether we were sick, was just 1-2%, which seems pretty unlikely. Importantly, this fact has no impact on our conclusion. There is a lesson here: unlikely things happen, and since our data are constants, just saying that we were lucky or unlucky to get them means nothing on its own. What matters is the probability of the model (or parameters) given the data, which, via Bayes' Law, accounts for the space of models (or parameter values) being considered as alternatives.
Finally, notice that, even though the generative model still plays a key role in our inference, we are no longer actually generating anything. Our probabilistic calculations consist of evaluating PMFs or PDFs, not drawing random numbers from distributions (for now... eventually we will end up using monte carlo methods to draw from posterior distributions that we can't easily evaluate everywhere).
Example: measuring the flux of a source¶
Let's now work through a real, if simple, problem with a more clear link to astronomy.
Specifically, let's take our model for the brightness measured for some source in the sky from the Generative Models notes, and simplify it even more. We'll do away with the multiple pixels in this model, and just say that we've measured a total number of counts. This might be the case if our source is so small and distant that it's effectively point-like, and we just integrate the measured signal over the point-spread function of our telescope.
We know from first principles that the number of counts we measure will be Poisson-distributed, and that the average of that Poisson distribution is related to the average flux of the source by various multiplicative constants, such as the integration time. So let's boil this down to the simplest possible version of the experiment: we measured a number of counts and want to infer the mean of the Poisson distribution that generated the data. (We could always convert this to a flux later on.)
In other words, our model is now equivalent to the example in "Return to the (aside)$^2$" in the Generative Models notes, with this PGM:
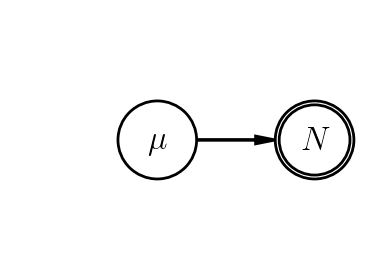 |
In this case, $N$ is our data (a measured number of counts) and $\mu$ is the parameter we want to infer. The corresponding expressions for the model are
- $\mu \sim \mathrm{prior}$,
- $N \sim \mathrm{Poisson}(\mu)$.
Let's go ahead and explicitly define the latter in code:
def sampling_distribution(N, mu):
return st.poisson.pmf(N, mu)
You may have seen the Poisson distribution before, but let's go ahead and visualize it for a few values of $\mu$ anyway.
N = np.arange(16)
plt.plot(N, sampling_distribution(N, mu=0.5), 'o', label=r'$\mu=0.5$');
plt.plot(N, sampling_distribution(N, mu=2.0), 'x', label=r'$\mu=2.0$');
plt.plot(N, sampling_distribution(N, mu=7.0), '+', label=r'$\mu=7.0$');
plt.xlabel(r'$N$', fontsize='x-large');
plt.ylabel(r'$P(N|\mu)$', fontsize='x-large');
plt.legend(fontsize='x-large');

Again, the sampling distribution is normalized over $N$ - each of these series would sum to 1.0 if we cared to check.
As a function of $\mu$ - the likelihood function - it looks like this:
mu = np.linspace(0.0, 15.0, 100)
plt.plot(mu, sampling_distribution(0.0, mu), '-', label=r'$N=0$');
plt.plot(mu, sampling_distribution(2.0, mu), '-', label=r'$N=2$');
plt.plot(mu, sampling_distribution(7.0, mu), '-', label=r'$N=7$');
plt.xlabel(r'$\mu$', fontsize='x-large');
plt.ylabel(r'$P(N|\mu)$', fontsize='x-large');
plt.legend(fontsize='x-large');

It so happens that $P(N|\mu)$, for fixed $N$, is also normalized as a function of $\mu$ in this particular case, but this will not be true in general.
To reach our goal of evaluating the posterior distribution, we'll need to specify the prior distribution for $\mu$. For the purpose of carrying on the example let's take $p(\mu)$ to be uniform over non-negative real numbers.
$\mu \sim \mathrm{Uniform}(0, \infty)$, or, equivalently, $p(\mu) = \mathrm{Uniform}(\mu|0, \infty)$.
On its face, this is a staggeringly stupid choice. If we claimed to know, a priori, that the source's flux is not infinite, it's hard to imagine anyone complaining about that assumption. If we tried to directly implement a uniform prior over this range in code, we would find that both the prior and, therefore, the evidence evaluate to zero, so that the posterior is NaN. Clearly what we mean is for the upper bound to just be a really big but finite number, and even then, in practice, there must be some values so implausibly large that no one would mind ruling them out to begin with.
When a PDF cannot be normalized, as in this case, it's called improper. Formally speaking, an improper prior is not necessarily a problem for us - it's possible (though not certain) for the posterior to be proper even if the prior is not.
Despite its seeming stupidity, this would not be an unusual choice of prior, and arguably is not unreasonable in practice. We'll see why, and discuss some equally reasonable alternatives, later in these notes. And so, we press onward.
def prior_distribution(mu):
big = 1.0e10 # can't deal with actual infinities here...
# The construction below allows mu to be scalar or an array. It's equivalent to (for scalar mu)
# if mu>=0.0 and mu<big:
# return 1.0/big
# else:
# return 0.0
return np.where(np.logical_and(mu>=0.0, mu<big), 1.0/big, 0.0)
We've now implemented 2 of the 3 terms on the RHS of Bayes' Law. The last is the evidence, which in general is challenging to compute. Thankfully we normally don't have to compute it explicitly if we just want to infer parameter values; for a given choice of model, we saw above that the evidence doesn't depend on parameter values so it serves only as an overall normalization. Working with an unnormalized version of the posterior is usually good enough, and we can always normalize it by brute force if we need to. In fact, we will often lazily use "posterior" to refer to just the numerator of Bayes' Law.
So, we now have everything we need to calculate $p(\mu)\,P(N|\mu) \propto p(\mu|N)$.
Say we measure $N=5$. Now what?
Broadly speaking, we have 3 options for computing the posterior.
- We could calculation it over a grid in parameter space. This is the brute-force approach: straightforward, but expensive in many dimensions. (In the previous example, there was a single parameter that could only take on 2 values, so it was no big deal.)
- If we work it out analytically, we might end up with an expression that happens to be a standard PDF with a bunch of known properties. This is super-efficient as far as our computers are concerned, but of course is only possible for certain forms of the likelihood and prior.
- We could produce random samples from the posterior distribution using Monte Carlo methods. In a sense, this is another brute-force method, but a more intelligent (less brutish?) one than looping over a many-dimensional grid.
Option 2 is available only for special cases, although we'll see later that some complex problems can be broken down into a series of special cases. Evaluation over a grid is a respectable solution for one- or two-dimensional parameter spaces. Usually once the number of parameters exceeds 2, it's best to go with Monte Carlo.
As we have a single parameter in this example, we'll stick with the first two options for now.
Numerical (on a grid) solution¶
In this 1-parameter, computationally light problem, evaluating the posterior (including its normalization) over a grid hardly presents a problem.
def posterior_distribution(mu, N):
# NB - This assumes mu is an equally spaced array covering the range where the posterior will be significantly
# different from zero.
post = prior_distribution(mu) * sampling_distribution(data_N, mu)
return post / (np.sum(post) * (mu[1]-mu[0])) # bother to normalize, so that the comparison to option 2 works below
Below, we compare the prior, likelihood and posterior for $N=5$. (Recall that the likelihood is not normalized over $\mu$ in general, though the prior and posterior are.)
data_N = 5
mu = np.linspace(0.0, 15.0, 100)
plt.plot(mu, prior_distribution(mu), '.', label=r'$p(\mu)$');
plt.plot(mu, sampling_distribution(data_N, mu), '-', label=r'$p(N|\mu)$');
plt.plot(mu, posterior_distribution(mu, data_N), '.', label=r'$p(\mu|N)$');
plt.xlabel(r'$\mu$', fontsize='x-large');
plt.legend(fontsize='x-large');

This may seem like a lot of trouble to go to to multiply the likelihood by a constant prior, when we allegedly don't care about the normalization of their product anyway. This is true. But, of course, the procedure would have worked just as well if we had chosen some other prior distribution for $\mu$.
Aside: the fact that $p(\mu|N)=P(N|\mu)$ exactly (as a function of $\mu$ for fixed $N$) follows from the fact that the Poisson $P(N|\mu)$ happens to be normalized over $\mu$ and our choice of a wide uniform prior. If both functions are normalized and differ by a constant factor, then that factor must be 1, of course. Again, this is not a general feature.
Analytical solution¶
If both the prior and likelihood are built from standard statistical distributions, we can sometimes take advantage of conjugacy.
Conjugate distributions are like eigenfunctions of Bayes Theorem. These are special cases for which the form of the posterior is the same as the form of the prior, for a specific sampling distribution. Naturally, the parameters of the posterior distribution are different from the parameters of the prior, and will depend somehow on the data.
In math, let $f$ be the form of the prior distribution, $g$ be the form of the sampling distribution, $x$ and $\theta$ stand for the data and model parameters of interest, and $\phi$ stand for the parameters specifying the prior distribution (these are often called hyperparameters). In this example, $\phi$ would be the endpoints of the Uniform prior, $(0,\infty)$. Then, if $f$ and $g$ are conjugate,
$f(\theta|\phi) \, g(x|\theta) = f\left[\theta\left|\phi'(\phi,x)\right.\right]$,
where $\phi'(x,\phi)$ is a function of the hyperparameters and data, specific to the conjugate pair, that we could work out or look up. (Up to now, we haven't been explicitly writing the prior as conditioned on its hyperparameters, because the hyperparameters have been fixed, but there's no reason we can't do so.)
Let's see how this works for the flux measurement example. Our Poisson sampling distribution is conjugate to the Gamma distribution, which has parameters $\alpha$ and $\beta$ and the PDF
$\mathrm{Gamma}(x|\alpha,\beta) = \frac{1}{\Gamma(\alpha)}\beta^\alpha x^{\alpha-1} e^{-\beta x}$ for $x\geq0$.
We could take this conjugacy as established fact (the Wikipedia says so!), but let's work it through this one time. For our problem, if we take a generic Gamma prior, we have
$p(\mu|\alpha,\beta) \, P(N|\mu) = \left[\frac{1}{\Gamma(\alpha)}\beta^\alpha \mu^{\alpha-1}\right] \left[e^{-\beta \mu} \, \frac{\mu^N e^{-\mu}}{N!}\right]$.
Collecting the terms that contain $\mu$ together, we have
$\quad = \frac{\beta^\alpha}{\Gamma(\alpha)N!} \, \underbrace{ \mu^{\alpha+N-1} e^{-(\beta+1) \mu} }$.
Comparing to the equation above, we can see that this has the form of a Gamma distribution over $\mu$. Now recall that we neglected to divide by the evidence so far, so this is not yet the posterior. Since we know that the posterior will work out to be a normalized PDF over $\mu$, we could legitimately conclude at this point that the posterior will be a Gamma distribution, with parameters $\alpha' = \alpha+N$ and $\beta' = \beta+1$. Alternatively, we could integrate the latest expression above to evaluate the evidence explicitly. Here it's convenient to multiply and divide in the constant that would make the Gamma PDF complete (the first term in the underbrace below),
$\quad = \frac{\beta^\alpha}{\Gamma(\alpha)N!} \frac{\Gamma(\alpha+N)}{(\beta+1)^{\alpha+N}} \, \underbrace{ \frac{(\beta+1)^{\alpha+N}}{\Gamma(\alpha+N)} \mu^{(\alpha+N)-1} e^{-(\beta+1) \mu} }$.
The collected terms above are now a normalized PDF, so that when we integrate over $\mu$ we will be left with only the coefficients out front. So, we've just proved that the evidence is
$P(N) = \frac{\beta^\alpha}{\Gamma(\alpha)N!} \frac{\Gamma(\alpha+N)}{(\beta+1)^{\alpha+N}}$,
and, indeed, if we had evaluated the full posterior, we would be left with
$p(\mu|N) = \frac{p(\mu|\alpha,\beta)\,P(N|\mu)}{P(N)} = \frac{(\beta+1)^{\alpha+N}}{\Gamma(\alpha+N)} \mu^{(\alpha+N)-1} e^{-(\beta+1) \mu} = \mathrm{Gamma}(\mu|\alpha+N, \beta+1)$.
One wrinkle though: we were planning to use a uniform prior for $\mu$. Generally, we shouldn't limit ourselves to choosing conjugate priors just because it's mathematically convenient. In this case, however, it so happens that the uniform prior we wanted is a limiting case of Gamma (with $\alpha\rightarrow1$ and $\beta\rightarrow0$), so we can take advantage of conjugacy after all.
Let's go ahead and update our PGM to explicitly show the hyperparameters in this case.
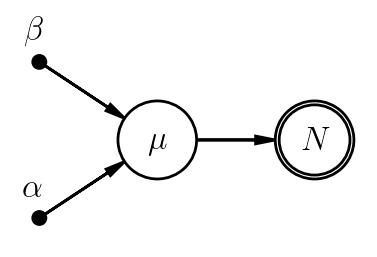 |
We can quickly verify that the analytic solution agrees with our grid calculation. (scipy.stats only implements the $\alpha$ parameter of the Gamma distribution in the intuitive way, making the inverse of $\beta$ a generic "scale" parameter, hence the acrobatics below.)
alpha = 1.0
beta = 0.0001 # putting in exactly zero here will get us into numerical trouble
plt.plot(mu, prior_distribution(mu), '.', label=r'grid $p(\mu)$');
plt.plot(mu, st.gamma.pdf(mu, alpha, scale=1.0/beta), '-', label=r'Gamma $p(\mu)$');
plt.plot(mu, posterior_distribution(mu, data_N), '.', label=r'grid $p(\mu|N)$');
plt.plot(mu, st.gamma.pdf(mu, alpha+data_N, scale=1.0/(beta+1.0)), '-', label=r'Gamma $p(\mu|N)$');
plt.xlabel(r'$\mu$', fontsize='x-large');
plt.legend(fontsize='x-large');

Choosing a prior¶
We've put it off for long enough: it's time to talk in depth about choosing a prior distribution.
Recall that the prior represents what we know before accounting for the data that we're analyzing at the moment. Depending on the circumstances we might choose a prior to
- encode the results of some previous experiment,
- encode a requirement of the theory underlying our model,
- encode an estimate of the uncertainty in the parameter (e.g. from theoretical considerations), or
- be "minimally informative" or to have minimal influence on the posterior.
The first of these in in some ways the most straightforward and least controversial. Suppose, hypothetically, we had acquired some data that measure the average density of matter in the Universe. Just to be difficult, cosmologists like to write this as $\rho_\mathrm{m} \propto \Omega_\mathrm{m} h^2$, where $\Omega_\mathrm{m}$ is the ratio of the matter density to the critical density, and $h$ is the Hubble constant in dimensionless form. If we expect our measurement to have comparable uncertainty to what has been done previously, then it might make sense to combine the two results. That is, we would set our prior on $\rho_\mathrm{m}$ equal to the posterior distribution of a previous (independent) experiment and use Bayes' Law to update our knowledge in light of the new data.
On the other hand, say our goal with the analysis is to use our data in conjunction with someone else's constraints on $h$ in order to determine $\Omega_\mathrm{m}$. In this context, we would call $h$ a nuisance parameter, i.e. a parameter of the model that we have to care about (our data depend on it, in the generative sense), but which we are not interested in. We might then adopt the prior $h \sim \mathrm{Normal}(0.72, 0.08)$ on the basis of the Hubble Key Project (Freedman et al. 2001). Our posterior distribution for $h$ would simply reproduce this prior, but we would be able to obtain constraints on $\Omega_\mathrm{m}$. (In the previous case, where only $\Omega_\mathrm{m} h^2$ is constrained by the prior or data, we would have a constraint on that combination, but the marginal distribution of either $\Omega_\mathrm{m}$ or $h$ would extend to infinity.)
The second and third options above are not functionally very different from the first, except that the prior information comes from theoretical considerations rather than a previous experiment. For example, in a cosmology analysis, we might require that the age of the Universe implied by the various parameters be greater than the age of the oldest stars in the Galaxy. (One could argue that this is still based on data, but it could nevertheless be a very hand-wavy bound.) Alternatively, a typical way to account for uncertainty in the gain of some instrument, if we're told by the designers that it's good to $\approx5\%$, would be to introduce a nuisance parameter representing this uncertainty, a place a $\mathrm{Normal}(1.0, 0.05)$ prior on it.
The last option is the one that people tend to have hang-ups about. What do we do if there is no previous measurement of our model parameters? What if there is no consensus about the theoretical prior expectation on a parameter? What if we want to show what our data accomplish, without that interpretation depending heavily on prior data or expectations? Even though there are arguably always prior expectations of one kind or another, this latter case usually applies to any parameters our data can measure (i.e. not nuisance parameters) - philosophy aside, we want to see how constraining our data are.
In this case, the solution would be to choose what is incorrectly known as an uninformative prior.
As a practical matter, we could call a prior uninformative if it is significantly wider than, and consistent with, the posterior distribution, as in the worked example above. But note two very important things about the solution above:
- There is, in the information theoretic sense, no such thing as a prior distribution that contains no information. All PDFs are somewhat informative.
- Consequently, there is still a choice to be made, since there is no uniquely zero-information prior.
The good news is that, given our practical definition of uninformative, it often doesn't matter exactly what prior we choose. As long as the likelihood function is "skinny" compared with the prior, their product will largely resemble the likelihood.
Things become stickier when the data simply aren't all that constraining compared with the reasonable range of parameter values. Of course, "reasonable range" is a prior expectation, but in this case, the shape of the prior PDF over such a range could well make a noticeable difference to the posterior. (For a given value of "noticeable".) What to do then?
Well, getting better data would be a good idea, if possible. But, in the meantime, all you can do is choose a prior PDF that you're willing to defend as reasonable, and see where that takes you, while acknowledging that it has some impact on the results. (Having "some impact" on the results is practically a tautology, but such statements have been known to mollify critics.)
Let's unpack the statement that there are no truly uninformative PDFs a bit more. Consider the flux measurement example above, with the context that, once we account for the exposure time, distance, etc., the luminosity of the star we observed is $L=\mu\,L_\odot$, with $L_\odot$ the Solar luminosity (just to keep things simple). So, for $N=5$, we think the star is probably a few times brighter than the Sun.
Now consider the following true statements about our uniform, semi-infinite prior:
- The a priori probability of $L$ being between 0 and 1$L_\odot$ is the same as it being between 1 and 2$L_\odot$.
- The a priori probability of $L$ being between 0 and 1$L_\odot$ is the same as it being between 10 and 11$L_\odot$.
- The a priori probability of $L$ being between 0 and 1$L_\odot$ is the same as it being between 1000000 and 1000001$L_\odot$.
- The a priori probability of $L$ being between 1 and 100$L_\odot$ is 99 times larger than it being between 0 and 1$L_\odot$.
Now, I am far from an expert on stars, but I do know that faint stars are vastly more numerous than bright stars, and our Sun is vaguely near the average. Technically, we would say that the luminosity function (number as a function of luminosity) of stars is decreasing. So, absent any other information about the star we observed, all of these statements appear dubious. The target should be less likely to be in the 1-2 $L_\odot$ range than 0-1 $L_\odot$, and much less likely to be in the 10-11 $L_\odot$ range. I'm pretty sure 1000000$L_\odot$ stars don't exist [citation needed]. And it's probably still more likely to be 0-1 $L_\odot$ than 1-100$L_\odot$, certainly not two orders of magnitude less likely.
In situations like this, the uniform distribution (loosely translated as "ignorance about the value of the parameter") might be less appropriate than a prior that's uniform in the log ("ignorance about the order of magnitude of the parameter"), that is $p(\mu) \propto \mu^{-1}$ (you can derive this using transformation using the change of variables formula). We could make the following true statements about the uniform-in-log prior:
- The a priori probability of $L$ being between 0.01 and 1$L_\odot$ is $\approx7$ times larger than it being between 1 and 2$L_\odot$.
- The a priori probability of $L$ being between 0.01 and 1$L_\odot$ is $\approx48$ times larger than it being between 10 and 11$L_\odot$.
- The a priori probability of $L$ being between 0.01 and 1$L_\odot$ is $\approx5$ million times larger than it being between 1000000 and 1000001$L_\odot$.
- The a priori probability of $L$ being between 1 and 100$L_\odot$ is the same as it being between 0.01 and 1$L_\odot$.
Qualitatively, this is a better match to our physical understanding of stars. You'll notice that it's become impossible to speak of zero luminosity, although that might not pose a problem (if we knew about the source ahead of time, it's likely that it occasionally emits a photon).
Naturally, there's also a case to be made for using a theoretical or observed luminosity function as the basis of the prior, in this situation. In fact, if we really needed the most accurate inference of the luminosity of this source, and the data were not very constraining, it would be a very, very good idea to do so.$^1$ But, as we're just illustrating a point, let's see how the uniform prior over $\log \mu$ changes our results. (Note that $1/x$ is also a limiting case of the Gamma distribution, so we can use the analytic machinery above once again.)
# uniform prior
alpha = 1.0
beta = 0.0001 # putting in exactly zero here will get us into trouble
plt.plot(mu, 300*st.gamma.pdf(mu, alpha, scale=1.0/beta), '-', label=r'$p(\mu)\propto\mathrm{const}$')
plt.plot(mu, st.gamma.pdf(mu, alpha+data_N, scale=1.0/(beta+1.0)), '-', label=r'$p(\mu|N)$');
# uniform-in-log prior
alpha = 0.0001 # putting in exactly zero here will (also) get us into trouble
beta = 0.0001 # putting in exactly zero here will (still) get us into trouble
plt.plot(mu, 300*st.gamma.pdf(mu, alpha, scale=1.0/beta), '-', label=r'$p(\mu)\propto \mu^{-1}$')
plt.plot(mu, st.gamma.pdf(mu, alpha+data_N, scale=1.0/(beta+1.0)), '-', label=r'$p(\mu|N)$');
plt.xlabel(r'$\mu$', fontsize='x-large');
plt.legend(fontsize='x-large');

I multiplied both priors by a constant above so that it would be easier to see the difference in their shapes. The choice of prior does make some difference in this case. (You can play around with different priors or values of data_N to see how the picture changes.)
In practice, the uniform and uniform-in-log distributions, with endpoints in the regime where the likelihood is essentially zero, are by far the most common choices when we want to be "uninformed". There are also strategies for choosing minimally informative priors, in some mathematical sense:
- The Jeffreys prior minimizes the Fisher information for a given problem. This is something like maximizing the width of the closest Gaussian approximation to the posterior in its multidimensional parameter space.
- Priors with maximal entropy for a given problem can be defined.
These are not identical, and in either case their function form depends on the form of the likelihood. Again, these are not often used (they rapidly become unwieldy as generative models become more complex), but you may run into them every so often.
It's worth repeating that there is no genuinely uninformative option. Your job is not to magically produce a fully "objective" prior (whatever that means), nor is it even to choose a prior that has the smallest possible influence on the result (again, whatever that means). It's just to choose a sensible and defensible option. If the decision really isn't obvious, yet has a noticeable impact on the results, then say so.
As we'll return to later, there are always some who interpret the need to make a decision about priors as some sort of disaster. It isn't. It simply means that, if the data are so inadequate that out choice of prior really matters, our job as analysts is to clearly state and defend our assumptions, and show their influence on the results. These are things that good scientists should be willing to do anyway.
Bayes' Law as a model for accumulating information¶
As alluded to in the discussion of prior distributions, above, Bayes' Law provides a seemless way to understand the refinement of knowledge as multiple data sets are accounted for. If we had not one data set but two ($x_1$ and $x_2$), we could write the posterior distribution for the parameters ($\theta$) as
$p(\theta|x_1,x_2) = \frac{p(\theta)\,p(x_1,x_2|\theta)}{p(x_1,x_2)}$.
If the two data sets are conditionally independent of one another, this factors to
$p(\theta|x_1,x_2) = \frac{p(\theta)\,p(x_1|\theta)\,p(x_2|\theta)}{p(x_1)\,p(x_2)}$
$\quad = \frac{p(\theta)\,p(x_1|\theta)}{p(x_1)} \, \frac{p(x_2|\theta)}{p(x_2)}$
$\quad = \frac{p(\theta|x_1) \, p(x_2|\theta)}{p(x_2)}$.
In words, analyzing the two data sets in tandem is equivalent to computing the posterior $\theta$ based on data $x_1$, and making that the new prior to be updated by data $x_2$. This is one of those completely reasonable and intuitive things that happens effortlessly, thanks to the principled, mathematical framework we're working within. Note that the "original" prior, $p(\theta)$, only appears once (as it should!), so this is not a matter of simply multiplying the posteriors we would get using those priors with each data set.
Just for fun, we can illustrate this with the flux measurement example from above, starting from a uniform prior and assuming a series of measurements: 5, 3, 6, 5, 5, 9, 6, 8, 5, 2. Notice how each subsequent posterior distribution becomes skinnier as they converge towards the value $\mu=5.5$ (used to generate these particular data).
data_Ns = [5, 3, 6, 5, 5, 9, 6, 8, 5, 2]
# uniform prior
alpha = 1.0
beta = 0.0001 # putting in exactly zero here will get us into trouble
plt.plot(mu, st.gamma.pdf(mu, alpha, scale=1.0/beta), '-');
# incorporate each datum
for data_N in data_Ns:
alpha = alpha + data_N
beta = beta + 1.0
plt.plot(mu, st.gamma.pdf(mu, alpha, scale=1.0/beta), '-');
plt.xlabel(r'$\mu$', fontsize='x-large');
plt.ylabel(r'$p(\mu|...)$', fontsize='x-large');

Exercise for the reader: in this particular case, thanks to the additivity of the Poisson distribution, we could also have just compressed the list of $N$s to a single datum and jumped right to an answer using the results from earlier and a little attention to the transformation of random variables. But where's the fun in that?
Finally, recall that the two data sets needed to be conditionally independent for the simple expressions above to work. If not, then $p(x_1,x_2|\theta) \neq p(x_1|\theta) p(x_2|\theta)$. This happens in cosmology, for example, when $x_1$ and $x_2$ are two different tracers of the same underlying density field. In this case, assuming $\theta$ refers to global cosmological parameters, $x_1$ and $x_2$ would not be conditionally independent - they each depend on local conditions like density that are implicitly marginalized over when writing $p(x_1,x_2|\theta)$. We could expand the model to explicitly incorporate all this local information (think of a plate over many cells in position, $x,y,z$). More likely, we would just do a new, joint analysis of $x_1$ and $x_2$ when we obtained the second data set. This lack of conditional independence is why you might hear the word "covariances" thrown around a lot in cosmology circles.
Previewing a couple of topics to come later:
- In practice, we are much more likely to have samples from a posterior distribution than a simple-to-evaluate expression as above. The equivalent of analytically incorporating an independent measurement is accomplished by importance weighting. That is, in any calculation involving the list of samples, we would weight each sample by its probability according to this second sampling distribution.
- One would normally want to check that the constraints from two data sets are consistent with one another before combining them. This is touched on in the "How to Avoid Fooling Ourselves" notes.
Posterior predictions¶
A quick way to test whether our fit to the data makes sense is to look at posterior predictions, something we will come back to with more rigor later. For now, we will just want to look at a posteriori predictions for our measurements, that is, preditions for what we might measure (based on the sampling distribution) for parameter values drawn from the posterior distribution. This may sound circular, and it is - that's the point! If the predictions we make from the posterior don't resemble the data that went into determining that posterior to begin with, that would be a good indication that our model assumptions have failed somewhere.
Let's do this for the latest incarnation of the example, in which we have a posterior distribution based on a whole list of measured $N$'s. What we would do is draw many possible values of $\mu$ from the posterior distribution, and, for each of those, draw one or more values of $N$ from the sampling distribution. From this we can build a histogram of predicted measurements (the posterior predictive distribution) to compare with the histogram of actual measurements, as below. (You may not be shocked to learn that, sometimes, the posterior predictive distribution is again a standard distribution with its own name. But we'll code up the random draws here anyway.)
nmc = 10000 # number of posterior predictions to make
bins = np.arange(0, 18, 2);
plt.hist(st.poisson.rvs(st.gamma.rvs(alpha, scale=1.0/beta, size=nmc)), density=True, label='PPD', bins=bins);
plt.hist(data_Ns, bins=bins, density=True, histtype='step', label='data');
plt.xlabel(r'$N$', fontsize='x-large');
plt.legend(fontsize='x-large');

Qualitatively, these two distributions look basically compatible. Making this kind of comparison quantitative is something we'll come back to, but, in the meantime, making simple comparisons of the data with posterior predictions is a very good habit to be in. Being older and wiser than a person who does not do this, you will get in the habit of doing so.
Just about everything is (or could be) an inference¶
We've mostly focused on one task so far, constraining parameters within a model, but this framework applies any time we want to draw a conclusion from data. We've already mentioned the task of selecting among competing models, i.e. inferring which model better explains the data. In addition, there's
- source detection: a particular case of model selection (no source vs a source, or various possible sources, or various numbers of sources...)
- interpolation and extrapolation: inference about the value of a function
- prediction: inference about something not yet measured
- and more
The next sets of notes will discuss how to quantitatively summarize posterior distributions, and put Bayesian analysis in context with other methodologies.
Endnotes¶
Note 1¶
I don't know if this is still done, but I used to hear the term "deboosting" thrown around in the context of galaxy cluster masses. The mass function of clusters is steeply decreasing, and masses are incredibly hard to measure precisely. Hence, the mass estimate one gets from using a uniform prior tends to be greater than the best estimate one could make by accounting for the mass function. This is exacerbated by selection bias, which we will get to eventually. Something similar happens in redshift estimation of sources of all kinds, given that the number of sources tends to be a strong function of redshift. The point is: one could go through some kind of convoluted "deboosting" procedure, or one could just choose a sensible prior and use the tools that Bayes, Laplace et al. gave us.