Notes: Generative Models¶
Containing:
- An introduction to probabilistic models, why we need them, and how to work with them
- Hopefully, some resolution of the frequently confusing key ideas from the overview: (1) data are random, and (2) data are constants
Models and inference¶
The basic inference problem we will be concerned with can take several forms, including
- inference about what values of the parameters of a model are preferred by the data
- inference about whether the data prefer one model over another (model selection)
- inference about data we might gather in the future (prediction)
In all cases, being good scientists, we'll want to make statements about how certain we are of one conclusion vs another. As we'll see, this means we will need to get comfortable working with probabilistic statements.
But what exactly is this model referred to above? In physics, "model" refers to a mathematical description of some physical system that we're studying. It may be an imperfect description, but by expressing it mathematically we should be able to calculate things and all agree on the answers, given the assumptions.
In statistical analysis, "model" means nearly the same thing. Specifically, we deal in generative models, meaning models that include not just the system we're interested in learning about, but also any additional processes required to describe the production (generation) of the observed data. The necessity of including everything up to the production and recording of data makes generative models more comprehensive than the theoretical models we usually deal with in physics, but the basic idea of providing a mathematical description of what we're studying is the same.
In other words, a generative model is a formal recipe for producing the data we observed, including
- physical processes happening out there in the Universe
- instrumental effects and the measurement process
- any computations done prior to calling the result "the data"
It has to be said that no generative model will ever completely capture the process of generating the data in full detail - or if it did, it would be too large and cumbersome to use. Nevertheless, this is our conceptual starting point.
We could equally well think of a generative model as a procedure for producing mock data sets that should be statistically equivalent to the one we observed.
If we do think of model building in the sense of simulating potential data for a moment, the first two bullets above will generally require us to introduce some randomness. Conceptually, there are different reasons why a given step in the data production recipe might include randomness:
- It may be intrinsically random (e.g. quantum mechanical)
- It may be random in the classical statistical mechanics sense, i.e. the system is so complex that its detailed state is unknowable, such that we can only make statistical statements about it
- It may be effectively random, in the sense that there is some important parameter that in reality has a fixed value, but that we simply don't know.$^1$ We could, however, vary its value according to some probability distribution when we generate different mock data sets, thus somehow propagating our ignorance of this parameter to the final result. (Note that this bullet is simply a generalization of the previous one.)
The upshot is that, while we can think of a generative model as a recipe (or pseudo-code) for simulating mock data, many of the steps in that recipe would involve invoking a random number generator. When we do inference with real data, it's the Universe randomizing things (and/or our ignorance making them effectively random). This is the sense behind the first key idea from the overview notes: "All data we collect include some degree of randomness."
Aside: but, also, data are constants¶
An example will help explain this.
Consider the following amazing cartoon of the process of capturing an image of some source (let's say a star) in the sky.
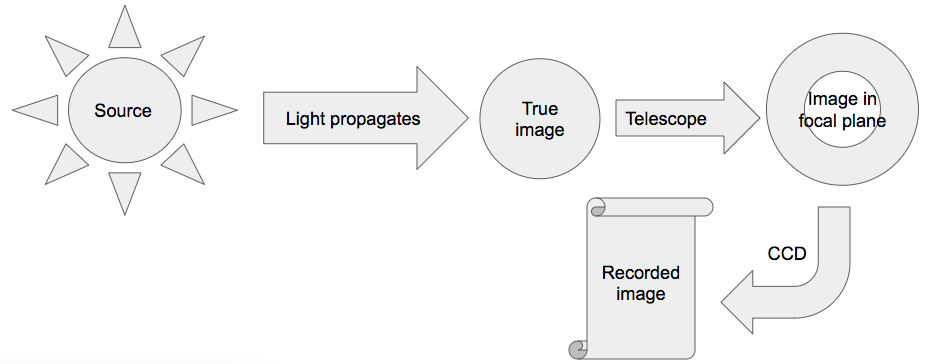 |
We could begin sketching out a generative model this way:
- There is a star, whose physical model would include things like surface temperature and luminosity.
- Light from the star travels to us (specifically, to just in front of our telescope). This part of the model might involve things like Doppler shifting, extinction and reddening (before reaching the Earth), possibly the cosmic expansion, and absorption and smoothing (in our atmosphere).
- The telescope optics focus the light, imparting some vignetting and aberration on the way. After going through a filter to isolate a certain range of wavelengths, it arrives at the focal plane, just above the imaging detector.
- Light hits the detector, is converted to an electronic signal (with some imperfect efficiency), and is read out (again, with some imperfect efficiency).
- The signal that has been read out is recorded to a hard drive. It is now "the data". (Yes, the data would also include unwanted signals like cosmic rays and dark current. We're keeping it simple.)
This is where the symmetry between simulating mock data and doing inference with real data ends. If we're simulating, we can go forth (after specifying the above more concretely in code) and produce as many mock images as we like. If instead we've done a real observation, we get the image (or images) that we recorded. In that context, the statement that data are constants just says that we define the generative model as including everything up to the point when the data are recorded, in particular including all the steps that involve randomness or uncertainty.
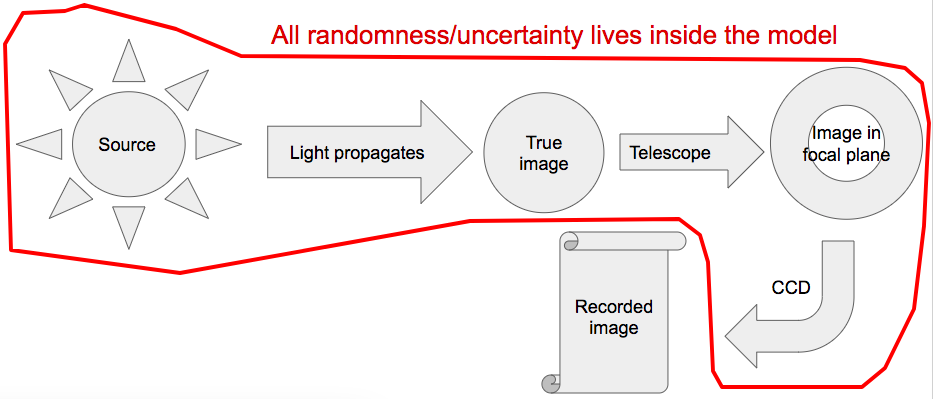 |
One way to think about this is that, in the context of inference, the job of the model is to make a prediction for the specific values that comprise the data, not just for some idealized, intermediate quantity (e.g. the "true image" above). Once recorded, the data are fixed, and the only question is whether the model is consistent with being able to produce them.
(Aside)$^2$: but what about error bars?¶
... you might reasonably ask at this point. Don't the data have error bars that allow them to be compared with a model for the true image? Isn't that the point of error bars?
The short answer is no, the data do not have error bars. Error bars are a delusion.
Here's the thing to keep in mind: once we have data, our job is (usually) to find the parameters that get the model to accurately predict those data. So, sources of "error" (things that introduce variability into the measured value) logically belong to the model, and become part of the prediction. They do not belong to the data.
The slightly longer answer is yes, often (but not always) it is possible to define an "error bar" and get away with thinking of it as associated with a given datum rather than as an uncertainty of the model's prediction. However, the "not always" is key. We will, therefore, stick with the "data are constants" maxim until we can discuss the specific circumstances when this shortcut is justified. Doing so will avoid some common and serious pitfalls, I promise.
To belabor the point slightly more, consider a simplified version of the above example (in which I will lean on simplified, "rule of thumb" stats as it is usually taught). I've measured the number of occurrences of a rare event in my detector in some time (say, photons from a very dim star). I recognize that most of the generative model will boil down to calculating the predicted mean number of photons we expect to detect in that time, with the actual number recorded being given by the Poisson distribution for that mean.
Say I measured 9 blips. What's the error bar? Well, I remember that error bar usually means "standard deviation", and the standard deviation of the Poisson distribution is the square root of its mean. My best (and only) estimate of the mean is the number that I got, 9. So, $9 \pm 3$.
What if I had measured just 1 blip? Via the same logic, we would call that $1 \pm 1$. Ok.
And if I had measured zero blips, then... $0 \pm 0$?
At this point in the hypothetical scenario (which is totally not based on a real story, I swear), I would be scratching my head and realizing that I wasn't sure what question the error bar was supposed to be answering. If the plan was to use the measured number of blips $\pm$ error to estimate the underlying Poisson mean (or some upstream quantity like the star's flux) and its uncertainty, then this last case is clearly nonsense. Measuring zero photons doesn't mean that the star has a flux of zero with absolute certainty, just that it's very dim (and/or the observation was very short, and/or the telescope was very small). But surely there are non-zero if small fluxes that my measurement does not rule out. Instead of getting caught up assigning fictitious error bars to the data, I should have instead accepted that they are constants, and focused on inferring (with uncertainties) the thing that I actually cared about, the star's flux. We'll see how to do this soon.
A key feature here is that the uncertainty in the prediction of our generative model depended on the model parameter value - it could not be something attached to the data independent of the model. The centrality of the Poisson distribution in this case made that explicit, but this is the general case. We should be thinking of uncertainties as belonging to the model by default, and recognize that attaching them to the data as "error bars" is a shortcut that is only sometimes justified.
Specifying generative models¶
Now that you understand that data are simultaneously random and constant, and do not have error bars, or at least are sick of hearing about it and ready to move on, let's see how to more concretely write down a generative model.
The first two highly recommended steps have already been done above, namely:
- draw a cartoon of how the data are generated
- sketch out in words what is happening in the cartoon
You might recognize these as excellent pieces of advice also frequently given to (and ignored by) introductory physics students. They also apply here. Being older and wiser than an introductory physics student, you will not ignore them.
To avoid getting bogged down in too many astrophysical specifics, let's simplify the example above slightly, while also introducing some notation.
Our measurement is the number of counts in each pixel. (For the uninitiated - the raw form of almost all astronomical data is a number of counts/activations/events recorded by a detector. In fact, the raw form of almost any scientific data is a non-negative integer.)
- There's a star emitting light, whose properties are parametrized by $\theta$. (This would include, for example, luminosity, distance from us, and perhaps temperature, metallicity, spectral type, ...)
- From $\theta$, we can determine the average flux falling on a given pixel $k$, $F_k$.
- Given the exposure time of our observation, $T$, $F_k$ determines the average number of counts expected, $\mu_k$. (There are also conversion factors related to collecting area, efficiency, etc. - we'll subsume all of those into $T$, and assume we know exactly what $T$ is.)
- The number of counts measured in a pixel, $N_k$, is a Poisson draw, given the average $\mu_k$.
To be explicit, this is significantly simplified from the more general example above. In particular, the weighty word "determine" appears a couple times. This means we will not be modeling randomness in those steps (think "deterministic").
We can reduce this to shorthand - think of it as statistical pseudo-code, as follows:
- $\theta \sim $ prior
- $T =$ known
- $F_k \Leftarrow \theta,k$
- $\mu_k \Leftarrow F_k,T$
- $N_k \sim \mathrm{Poisson}(\mu_k)$
Here "$\Leftarrow$" indicates a deterministic dependence, and "$\sim$" means "is distributed as" (not "scales like" as it is often used in physics, nor the fuzzy "is kinda sorta like" as it is also sometimes used in physics). Hence, every bullet corresponds to a line of code that we could, in principle, write if we were planning to simulate mock data according to this model, with "$\Leftarrow$" indicating ordinary function calls and "$\sim$" indicating calls to a random number generator. $\mathrm{Poisson}(\mu_k)$ should be read as the Poisson distribution with parameter $\mu_k$, so the last line is equivalent to wtiting $P(N_k|\mu_k) = \mathrm{Poisson}(N_k|\mu_k)$ (see "Notation" at the very end of the Essential Probability notes). When we refer to the "probabilistic expressions" associated with a model, we generally mean pseudo-code like this.
I haven't written a specific probability distribution (PDF) in the first line, although we would need to do so in practice. The right hand side of that line is a distribution encoding what we know about the values of $\theta$ before accounting for what we learn from the data (remember, this is also a recipe for simulating mock data), known as the prior distribution. We will discuss this much more in the Bayes' Law notes (and beyond), so for now just know that some concrete distribution would need to be specified in practice, without minding the details.
Naturally, one can simplify this. You could imagine eliminating $F_k$ and $T$ by writing $\mu_k$ as a more complicated function of $\theta$ for example. The risk, just like in any other context, is that doing so might obfuscate the inner workings of the model to the point where we are more likely to get confused and make mistakes.
Jargon¶
Other than the data, all quantities in the model are fair game for the term parameter. It's less common to refer to deterministic or "known" quantities this way, but you may still see it. The parameters that specify the prior distribution are sometimes called hyperparameters, but this is just a convention; functionally they are equivalent to any other non-data quantities in the model.
You might also come across the term nuisance parameter. This is also not a particularly well defined term, serving only to express that the speaker doesn't actually care about the value of the parameter in question. Again, the formalism doesn't make any disctinction between nuisance and non-nuisance parameters; it's only a question of what's (subjectively) interesting or not.
Visualizing generative models¶
As you might imagine, this linear psuedo-code representation can become unwieldy for more complex models. A useful complement is a visualization called a probabilistic graphical model (PGM) or, less often, a directed acyclic graph (DAG). Both names are apt; DAG says what it is, and PGM says what it's for. We'll call these beasts PGMs.
The PGM in statistical inference has a somewhat analogous role to the free-body diagram in introductory mechanics. They're both extremely helpful visual tools, whose use will avoid any number of pitfalls later on. Likewise, every generation of students assumes that of course it doesn't need to bother with drawing these things, and turns out to be mistaken. Being older and wiser than an introductory mechanics student, you will not fall for into this trap.
Here's the PGM corresponding to the model above:
The PGM consists of several components, which provide a shorthand for the probabilistic relationships we've been sketching out:
- Nodes (dots and circles) represent PDFs for parameters; note that it's often helpful to explicitly label the distribution, as with $N_k$ above
- Edges (arrows) represent conditional relationships
- Plates (rectangles) represent repeated model components whose contents are conditionally independent
You can think of conditional relationships as comprising those things that are within "one degree of separation". For example, above we see an edge connecting $\mu_k$ to $N_k$, indicating a conditional dependence of $N_k$ on $\mu_k$. Clearly, $N_k$ also depends on all of the other parameters that "feed into" it via $\mu_k$. But, once $\mu_k$ has been specified (conditioned on, in math words), there is no longer any additional dependence of $N_k$ on the other parameters. So, we would say that $N_k$ is conditionally independent of $\theta$, $F_k$ and $T$. Another way to think about conditional dependences is as the things appearing on the right hand side of the line of code you would write to evaluate $N_k$ (as we'll do below). As defined above, the plate indicates that $F_k$, $\mu_k$ and $N_k$ are conditionally independent of $F$, $\mu$ and $N$ for any other pixel than $k$ (all of the pixels depend on $\theta$ and $T$, but that's the extent of their interaction).
There are multiple types of nodes:
- Circles represent a generic PDF. This parameter is a stochastic ($\sim$) function of the parameters feeding into it.
- Double circles indicate measured data - they are stochastic ($\sim$) in the context of generating mock data, but fixed in the context of parameter inference.
- Points represent a delta-function PDF. This parameter is a deterministic ($\Leftarrow$) function of the parameters feeding into it.
These specific visual representations are unfortunately not universal, but this is the convention we'll stick with.
There is an ambiguous case not listed above, namely things that are measured but which we assume are not random at all. The key word here is "assume"; measured things are data, and conceptually any measurement has some randomness associated with it. However, there are plenty of situations where we can reasonably assume this randomness is small enough to be neglected for our particular purposes. The exposure time in this problem, $T$, is one example: it does have to be measured by a clock, and the number we record won't be perfectly accurate, but typically that inaccuracy would be utterly insignificant. By convention, we represent these things as points, emphasizing their (assumed) precision over their data-ness. Since they are assumed to be known perfectly, there is nothing interesting to be represented by a double circle (i.e. no PDF for generating data), and equivalently the generative model does not need a prescription for producing them.
Notice a few things about the PGM for this example:
- By the time we had broken down our model into a list of expressions, it was described in terms of conditional relationships. This is also reflected in the connectedness and directionality of the PGM, as described above.
- The PGM displays the conditional relationships among the parameters of the model, but is not a substitute for the list of expressions, since it doesn't tell us specifically what each PDF is.
Because the model formalizes a recipe for producing data from some source, it must have a clear beginning and end. In other words, there can be no way to go backwards or orbit by following the arrows (hence the "directed" and "acyclic" in DAG).
Generating from generative models¶
I've claimed multiple times that the probabilistic expression/PGM of a model are pseudo-code for generating data. Let's make it explicit by turning the generative model above into actual code. Of course, to do so, we'll need to fully specify the things that were left vague above.
For the purpose of this example, let's say that $\theta$ stands for the star's intrinsic luminosity, $L$, and distance from us, $d$. In the PGM, we would simply replace the $\theta$ node with these 2 nodes, both feeding into $F_k$.
We also need to specify their prior PDFs. This is something we'd want to think carefully about if our job were to infer $L$ and/or $d$ from real data, but for the purpose of generating mock data, the only question is: what distribution of parameter values do you want to generate mock data from? So, I'll choose something simple below. Similarly, we'll need to specify the deterministic relationships in the model, including how the star's flux is spread among the pixels (I'll assume this is described by a Gaussian-like function, just to have something to plug in).
With a certain amount of creative invention, our list of expressions might be
- $L \sim \mathrm{Normal}(161.8, 10)$
- $d \sim \mathrm{Normal}(3.142, 0.2)$
- $T = 12$
- $F_k = \frac{L}{4\pi d^2} e^{-0.5(k-5)^2}$
- $\mu_k = F_k T$
- $N_k \sim \mathrm{Poisson}(\mu_k)$
Translated into code (again, note that only the conditional dependences show up), this is:
import numpy as np
import scipy.stats as st
npix = 11 # number of pixels
L = st.norm.rvs(1.618e2, 10.0)
d = st.norm.rvs(3.142, 0.2)
T = 12.0
F = np.zeros(npix)
mu = np.zeros(npix)
N = np.zeros(npix)
for k in range(npix):
F[k] = L / (4.0 * np.pi * d**2) * np.exp(-0.5*(k - 5.0)**2)
mu[k] = F[k] * T
N[k] = st.poisson.rvs(mu[k])
... and one realization of the counts in each pixel is:
N
array([ 0., 0., 0., 4., 14., 22., 14., 2., 0., 0., 0.])
Do note that the code above is not efficient in python, but that wasn't our purpose here. In practice, one should never do with a for loop something that can be done through array-aware functions. We would probably also be more interested in the distribution of generated data sets than in a single realization, and would therefore have written the code to do these operations for many random values of L and d.
Interpreting generative models¶
As well as a recipe for producing data, we can also (more formally) interpret a generative model as encoding the joint probability of all our model parameters and data,
$P(\mathrm{data},\mathrm{params}) = P(\mathrm{params}) P(\mathrm{data}|\mathrm{params})$
This equality is just the definition of conditional probability (if this seems unfamiliar, or if you'd like some review, see the Essential Probability notes). More generically, the joint probability of A and B is the product of the marginal probability of A (the probability of A, irrespective of B) and the probability of B given (conditional on) A: $P(A,B) = P(A) P(B|A)$. Symmetrically, $P(A,B)$ is also equal to $P(B)P(A|B)$.
The particular factorization above is sensible given the way we normally interpret a PGM: there are some parameters, and data are generated conditional on their values. To introduce some terminology, $P(\mathrm{params})$ is the prior distribution (again, much more on that coming later), and $P(\mathrm{data}|\mathrm{params})$, is called the sampling distribution. We use this particular factorization because it corresponds to the pattern of conditioning within a generative model, as illustrated in the example above: first the model parameters take on some values, and then (conditional on those values) data are generated. Making the connection between this factorization and the alternative one, $P(\mathrm{data}) P(\mathrm{params}|\mathrm{data})$ is the key to performing inference, as we'll see in Bayes' Law.
To be explicit, then, the joint probability encoded in the PGM above would just come from multiplying all the PDFs represented:$^2$
$p(\theta,T,\{F_k, \mu_k, N_k\}) = p(\theta)\,p(T) \prod_k P(N_k|\mu_k)\,p(\mu_k|F_k,T)\,p(F_k|\theta)$.
Here we can factor the PDFs associated with each pixel, $k$, into a product because of their conditional independence. The assumption that data points are (conditionally) independent isn't always valid, but it is very common, and the resulting factorization is convenient.
Several of the PDFs in the above expression are delta functions, according to our model, so we might be forgiven for simplifying them away. To be maximally pedantic, we will marginalize over the parameters in question. Mathematically, this translates to doing a sum or integral over all possible values of the parameters. We would write this as
$p(\theta,\{N_k\}) = \int dF_k\,d\mu_k\,dT\; p(\theta,T,\{F_k, \mu_k, N_k\})$
$\quad = \int dF_k\,d\mu_k\,dT\; p(\theta)\,p(T) \prod_k P(N_k|\mu_k)\,p(\mu_k|F_k,T)\,p(F_k|\theta)$
Note that once a quantity is marginalized over, it no longer appears as part of the expression on the left hand side.
$p(T)$, $p(\mu_k|F_k,T)$ and $p(F_k|\theta)$ are all delta functions. For example, $p(T) = \delta(T-T_0)$, where $T_0$ is the known value of $T$. If the deterministic relationship "$\mu_k \Leftarrow F_k,T$" is, say, $\mu_k=F_kT$, then $p(\mu_k|F_k,T) = \delta(\mu_k - F_kT)$. $p(F_k|\theta)$ would have a similar form, albeit presumably with a more complex function providing the deterministic value of $F_k$. Since these delta functions are all zero except at the value that makes their arguments vanish, the integrals simplify to
$p(\theta,\{N_k\}) = \underbrace{p(\theta)} ~ \underbrace{\prod_k P\left[N_k|\mu_k(\theta,T)\right]}$,
which is, in simplified form, the prior distribution of $\theta$ multiplied by the sampling distribution for each observation, $N_k$.
Was there a point to all this formalism? Granted, in the context of simulating mock data, it isn't obviously helpful to be able to compute the probability of a specific set of parameter and data values being generated by the model. However, when doing inference from real data, computing such probabilities is the name of the game. The fact that we can read the joint probability of a model, in a sensibly factorized form, off of a PGM will be useful, going forward.
Return to the (aside)$^2$¶
Coming back to my apocryphal confusion about error bars, let's see how thinking generatively might have avoided the pitfall described way above. The underlying goal seems to be to determine the value of the mean rate underlying the blips in the detector, and its uncertainty. That this was never explicitly and simply stated in the original aside is itself a red flag that we're confused, so let's say it now: we measure a number of blips and want to learn the mean blip rate (equivalently, the expectation value of the number of blips in whatever our observation time was) from the measured number of blips. This would lead us to the model
- $\mu \sim$ prior
- $N \sim \mathrm{Poisson}(\mu)$
and the PGM:
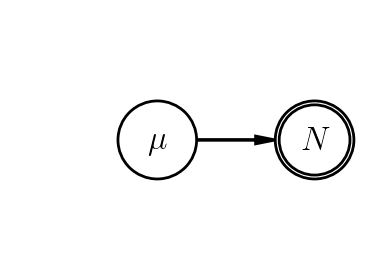
Importantly, this is a complete generative model, and there was no need to invoke an error bar to generate the data - the randomness in our measured data is entirely encoded by the Poisson distribution itself. Granted, this is not yet an inference; the process of going from a specified model to constraints on model parameters will be the subject of the next few notebooks.
A more complex example¶
The process of specifying a generative model - that is, translating a real-world scenario into a PGM and probability expressions with enough specificity to act on - is one of the hardest tasks we will face. Right now, it's probably still mysterious how this helps us learn from actual data that we have, but even so it could be worth diving into a more complicated example based on a real analysis.
Galaxy cluster center offsets
You've measured the centers of a sample of galaxy clusters in two ways: by choosing a brightest cluster galaxy (BCG) and by finding the centroid of each cluster's X-ray emission. The difference between the two should say something about the fidelity of the BCG identification method, among other things. The BCG positions are determined essentially perfectly (that is, we can assume that the measured BCG position is its true position), but the measured X-ray centroids come with a Gaussian statistical uncertainty of typically $\approx30$ kpc (standard deviation) in both the $x$ and $y$ directions. The underlying model is assumed to be that the BCG and true X-ray centroid coincide perfectly in a fraction $f$ of clusters. In the remaining clusters, the true X-ray centroid and BCG are displaced in $x$ and $y$ according to a Gaussian of some width (the same width in each direction).
There are a few possible strategies for getting started:
- Go forward from the most fundamental part of the model and try to get all the way to the data (i.e., the generative direction).
- Start from the data and try to work backwards to the beginning of the generative process.
- Just start drawing nodes, edges and plates and hope to eventually make them all connect up.
All of these (even the 3rd) are fine, and it might be a matter of taste which is best. In this case, I would go back to the description of the problem and just try to define all of the parameters we'll need:
- BCG positions: $x_{\mathrm{BCG},i}$, $y_{\mathrm{BCG},i}$, with $i$ indexing the clusters. From the description thse will be circled-point nodes in the PGM (data that we assume are generated without randomness).
- Measured X-ray centroids: $\hat{x}_i$, $\hat{y}_i$. The hat is my little reminder that these are measured rather than true X-ray centroids. These will be double circles (regular data).
Given the symmetries in the description, it would have been fine for $x$s and $y$s to be expressed as vector position $\vec{x}=(x,y)$, but let's press on. At this point, I think we've defined all the actual data we're given. But we also need
- True X-ray centroids: $x_i$, $y_i$.
- This Gaussian width (that we somehow know... typical) describing how measured X-ray centroids differ from true centroids: $\tau$. The problem is just asserting this thing, so I guess we will call it a point and more on with our lives. (Maybe circled $\tau_i$ if we had more knowledge of where it comes from...)
- The fraction of clusters where the true centroid and BCG coincide perfectly: $f$. This is a circle. (Generically, if we don't know something and it's not data, assume it's a circle.)
- The Gaussian width relating the BCG position to the true X-ray centroid in a fraction $(1-f)$ of cases: $\sigma$. (Circle.)
The model only deals with position offsets, not absolute positions. In addition, we're told the BCG positions are known precisely. So there's no harm in simplifying our lives a little by replacing $x_i, y_i$ above with offsets from BCG position $i$: $\Delta x_i, \Delta y_i$. We can do the same for the measured centroid offset, although I'll be a purist and say that the data are still absolute centroid positions.
This business with the PDF of th BCG-centroid offset being zero some of the time and non-zero some of the time is annoying, but we can still build a PDF for it, namely $p(\Delta x_i, \Delta y_i|f, \sigma) = f \delta(\Delta x_i) \delta(\Delta y_i) + \frac{1-f}{2\pi\sigma^2} \exp \left[-\frac{1}{2}\left(\frac{(\Delta x_i)^2}{\sigma^2} + \frac{(\Delta y_i)^2}{\sigma^2}\right)\right]$. That seems like a relatively complicated thing to be hiding in a circle on a PGM, though, so I will make it more explicit by doing something that isn't necessarily obvious: introducing:
- An indicator variable: $g_i$ (circle). This tells us whether a given cluster belongs to the perfectly aligned subset of clusters ($g_i=1$) or not ($g_i-0$).
The PDF for $\Delta x_i, \Delta y_i$ still has the same complicated form (with $g_i$ in place of $f$), but having this extra parameter around is an reminder that the complexity is there. Again, this isn't actually necessary, but there are times when such additional parameters can be useful.
One day I'll animate the process of building up the PGM as we work through the text above, but until then you'll have to be satisfied with the end result. Does it make sense given the description in words? (Note that the $\tau$ doesn't "belong" to the plate - it has no subscript $i$ - despite being within it. Sometimes compromises are necessary to make things fit.) (Also note that there is a plate! The problem didn't say anything about the clusters being dependent on one another, so we assume conditional independence.)
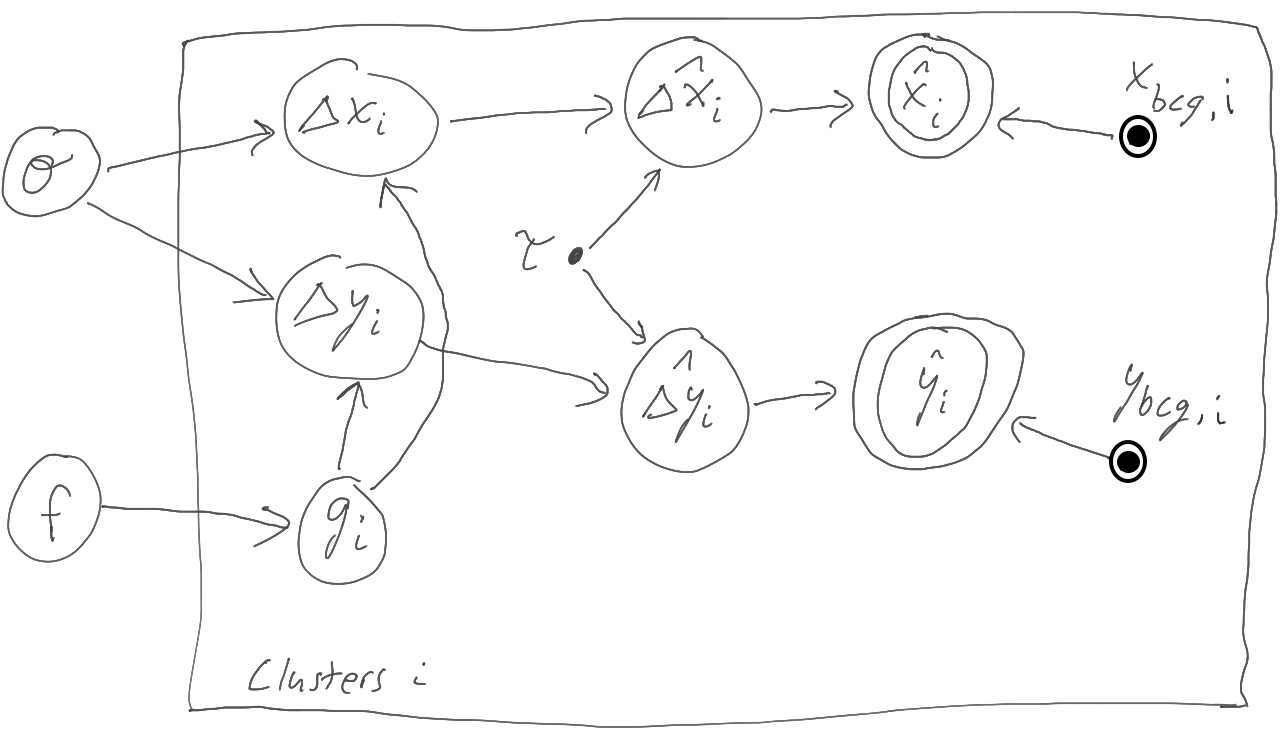
To be clear, this isn't the only "correct" PGM one could draw - the introduction of $g_i$ was a choice, as was the use of offsets in some places and absolute positions in others.
We can also write down probability expressions based on this PGM at this point, apart from specifying the priors:
- $f \sim$ prior
- $\sigma \sim$ prior
- $\tau =$ known
- $g_i \sim \mathrm{Bernoulli}(f)$
- $p(\Delta x_i, \Delta y_i|g, \sigma) = g \delta(\Delta x_i) \delta(\Delta y_i) + \frac{1-g}{2\pi\sigma^2} \exp \left[-\frac{1}{2}\left(\frac{(\Delta x_i)^2}{\sigma^2} + \frac{(\Delta y_i)^2}{\sigma^2}\right)\right]$
- $\Delta \hat{x}_i \sim \mathrm{Normal}(\Delta x_i, \tau)$
- $\Delta \hat{y}_i \sim \mathrm{Normal}(\Delta y_i, \tau)$
- $x_{\mathrm{BCG},i}, y_{\mathrm{BCG},i} =$ known
- $\hat{x}_i = x_{\mathrm{BCG},i} + \Delta \hat{x}_i$
- $\hat{y}_i = y_{\mathrm{BCG},i} + \Delta \hat{y}_i$
Since the PDF for $\Delta x_i, \Delta y_i$ is not a standard one, I've written it out explicitly as "$p(\Delta x_i, \Delta y_i|\ldots) = \ldots$" instead of using the "$\Delta x_i, \Delta y_i \sim \ldots$" notation.
You'll get lots of practice with this kind of thing (mostly in simpler cases) in the Generative Models tutorial, and repeatedly throughout the rest of the course.
Jargon¶
The model above is an example of a hierarchical model, one where the PDF of the data is specified by some parameters, whose PDFs are specified by some parameters, ..., eventually ending in prior PDFs for parameters somewhere up the line. This kind of structure is ubiquitous when we are modeling classes of objects, so we'll see it quite often later on.
Parting thoughts¶
It may seem nonintuitive to begin a course on statistical methods with a lesson on generative models, which might appear to be intended for creating fictional data. So, let's take a moment to reiterate what a generative model is, what it is not, and why we're doing this.
A generative model is a model in the physics sense - that is, a conceptualization, probably approximate, describing some system or process. In this case, the model is meant to describe the process by which the numbers we call data come to be. It will typically, therefore, include a physical description of whatever object we're looking at, as well as a description of the measurement process itself. Also typically, a generative model will begin with the physical model, and end with the data, since that's the generative (causal) direction.
Critically, while the generative model incorporates details of how our measurements are made, it is something we should be able to design without having seen or even collected the data. We are not yet in a position to say what values of the model parameters would produce the observed data. What's important is that the model be complete enough to make predictions about possible data that could be produced by a given set of parameter values.
A generative model is not a description for what we will do with the data to learn the parameter values, or about the physical model more generally. This is a key conceptual distinction from the way statistical analysis is most commonly taught, in which the focus is on doing calculations with the data to produce estimates of the parameters of an underlying model. Reiterating and expanding on the points above, the generative process encoded in the model may not depend in any way on the data themselves - the data are the endpoint. We will, of course, be doing calculations that involve the data very soon (starting with Bayes' Law). But, before that, we need to be able to describe with concrete, numerically evaluatable relationships, the path from the physical model to the recorded data.
This brings us to why we are starting with this subject: because a complete generative model automatically specifies all of the ingredients we will need to do Bayesian inference. The information encoded in the generative model, combined with the specific values of the data, fully determines what our inferences will be. Since the data are constants, it's not entirely unreasonable to say that the analyst's main job is to build the appropriate generative model for them. (This ignores the sometimes daunting task of carrying out the actual computations... but we'll get to all that.) Building the appropriate model requires having an understanding of the measurement process and being clear about exactly what the data are. For example, the reason we identified the data as a number of counts in the flux-measurement example, rather than a "measured flux" derived by going backwards to $F_k$ through the relationships we enumerated, is that only for counts could we specify the random process involved in producing the data (Poisson, under typically satisfied assumptions).
In short, we begin our journey with generative models because they're absolutely fundamental to everything that comes afterwards. This course won't provide you with a menu of equations to plug through when handed data of one type or another. It will, we hope, provide you with the tools to draw inferences from data using the appropriate generative model for those data - and since you, not us, are the expert on your science and your data, the responsibility for building that model lies with you.
Endnotes¶
Note 1¶
If this bothers you, consider playing Frogger while blindfolded. The game is executing a fully deterministic program, so in reality there is no uncertainty about whether the frog will be smooshed if it hops into the road at a given time. The player is missing this key information, but can still, in principle, make predictions about how likely the frog is to be smooshed at any given time using probabilistic modeling. With repeated experimentation, they could even refine this model to make it more accurate. As far as the player is concerned, whether there is an obstacle in the road is functionally random, despite the underlying mechanics being non-random.
Note 2¶
We'll follow the convention of using capital $P$ for the probability of a discrete outcome, e.g. $P(N)$ where $N$ is integer-valued, or for a generic argument like "data". Probability densities over real-valued variables will get a lower-case $p$. The distinction between capital-$P$ Probability (aka "probability mass") and probability density doesn't matter too often, but occasionally can lead to confusion, so we'll try to keep them straight. (See the probability notes.)