Notes: How to Avoid Fooling Ourselves¶
Detection, Fishing, Experimenter Bias, and Consistency¶
In which we will
- see how detections/discoveries can be assessed in both the Bayesian and Frequentist frameworks
- consider the dangers of fishing expeditions
- introduce the issue of unconscious experimenter bias, and methods can mitigate it
- see how to quantify dataset consistency, when bringing multiple observations together
Detection¶
Source detection is different in character from parameter estimation. Initially, we are less interested in the properties of a new source than we are in its existence, which may not be known a priori. Detection is therefore a model comparison or hypothesis testing problem:
$H_0$: the "Null Hypothesis," that there is no source present
$H_1$: the "Alternative Hypothesis," that there is a source present, e.g. with flux $f$ and position $(x,y)$
Bayesian detection¶
Within Bayesian analysis, we calculate and compare the evidence for each model, $P(d|H_0)$ and $P(d|H_1)$. Their ratio gives the relative probability of getting the data under the alternative and null hypotheses (and is equal to the relative probabilities of the hypotheses being true, up to a model prior ratio).
Calculating the evidence ratio involves marginalizing over the alternative hypothesis' model parameters, given the prior PDFs that we assigned when defining $H_1$. Weakening the prior on the source position and flux (by, for example, expanding their ranges) makes any given point in parameter space less probable a priori. So, as we've seen, weaker priors decrease the evidence for $H_1$, making the detection less significant (but only linearly in the prior volume, remember). Choosing sensible priors that are consistent with the source(s) being searched for is therefore essential.
Frequentist detection¶
Instead of working towards the relative probabilities of two hypotheses, the frequentist approach is to attempt to reject the null hypothesis by showing that it would be too improbable for the data to have been generated by it. It turns out that the most powerful statistic to use in this hypothesis test is the likelihood ratio. ("Power" is defined to be the probability that the null hypothesis test is rejected when the alternative hypothesis is true.)
To find the likelihood ratio, one would maximize the likelihood for the parameters of each hypothesis, and form the test statistic
$T_d = 2 \ln \frac{L(\hat{\theta},\hat{\phi},H_1)}{L(\hat{\phi},H_0)}$,
where $\theta$ are the parameters describing the source and $\phi$ are any parameters shared by the two models (maybe the background level in this example). We then inspect the distribution of test statistics $T$ over an ensemble of hypothetical datasets generated from a model with no source (the null hypothesis), and compute the $p$-value $P(T_d > T)$. If $p < \alpha$ we then say that "we can reject the null hypothesis at the $\alpha$ confidence level." We could find the distribution of $T$ by simulation or by approximating it as $\chi^2$, as we did in when looking at model evaluation.
Fishing expeditions¶
In the frequentist world, the test statistic depends only on the estimated values of the source parameters, and reports the likelihood ratio between two discrete hypotheses. We need to account for the fact that we "went fishing" (i.e., we searched for the source throughout parameter space, perhaps scanning over potential source positions and fluxes).
One way to do this is the classical Bonferroni correction. If we carry out $m$ independent "trials" (models tested), and are aiming to detect at the $\alpha$ confidence level, we would expect to get a positive result by chance in a fraction $\alpha' = 1 - (1-\alpha)^m \lesssim m \alpha$ of cases. Even if the trials are not independent, this last inequality holds. The Bonferroni correction therefore involves comparing $p$-values to a threshold $\alpha / m$, in order to test (and report) at the $\alpha$ confidence level. This $1/m$ is sometimes referred to as the "trials factor," and the issue described here is known in the statistics literature as the "multiple comparisons" problem, and in (astro)particle physics as the "look elsewhere effect."
Perhaps unsurprisingly, there is something similar that happens in Bayes' world. Namely, imagine we've compared a no source model and $m-1$ alternative models, and consider the alternatives, a priori, to be equally likely. Then their prior probabilities will each be $\leq 1/m$, with the equality holding only if we consider the null (no-source) model just as implausible as any of the alternatives. In the case of source detection, however, we would be more likely to cast this problem as having a single alternative model with additional free parameters, in which case the penalty to the evidence that we suffer from marginalizing over wide priors accomplishes the same thing.
While we've described all this in terms of literal searches to detect or discover an astronomical source, identical logic applies to searches for potential correlations between different quantities or measurements. This is the context where you're most likely to encounter the issue of multiple comparisons in the wider world, especially now that so much of "data science" rests on vaccuuming up and analyzing enormous amounts of enormously low signal-to-noise data (though it's relevant for us, too). The classic fishing expedition consists of searching exhaustively for "significant" correlations among all the columns of a very large data table.
Post-Hoc Analysis¶
Expanding on the last point, consider the following scenario:
You take some data with the aim of fitting a linear relation. However, when you look at the data, it seems like a linear model won't be a good description, so you also fit a quadratic, and the posterior for the second-order coefficient is inconsistent with zero. The paper, naturally, notes that you have detected a departure from the simple linear model expected.
The issue here is that the data are used more than once: both for defining the model to be fit and also for fitting the parameters of the model. This is not necessarily forbidden. But we need to consider the possibility that the features that motivated using a higher-order model were only a random fluctuation, with the true model actually being just linear. We can't take the constraint on the second-order coefficient at face value because we only included it in the model to begin with because the data appeared to prefer it.
Note that this consideration would be moot if we had planned to test linear vs quadratic models from the beginning, before ever looking at the data. But, more generally, we need to be cautious of cases where many additional hypotheses are introduced (even when when they are not motivated by examining the data), simply because the chances of one of them randomly appearing significant increases. This, too, is known as fishing, and we would need to account for the number of tests done, as above. In Bayesian language, if we don't define our priors (in model space) ahead of time then they aren't priors, and we no longer have a mathematically unimpeachable basis on which to assign posterior probabilities.
Post-hoc analysis is unavoidably common in astronomy, since our science is so often driven by noticing something unexpected in new observations. This doesn't mean we shouldn't report new discoveries, just that we should recognize the possibility that we are being fooled. Ultimately, the most robust way to test new models is with new data.
Experimenter bias¶
A particularly insidious post-hoc analysis problem is "unconscious experimenter bias". It might look like this:
After producing some intermediate or final result, a researcher compares their findings with those of others or with prior expectations. If there is disagreement, the researcher is more likely to investigate potential problems before publishing, whereas if everything looks in agreement with expectations they might immediately publish.
In the worst case (short of actual fudging), a researcher might continue finding more and more bugs to fix, until the results come into line with expectations. (As Bayesians, we might ask: if your prior is so strong, why bother doing the experiment?) In the alternative hypothetical, the analysis might have just as many bugs, and the results might be completely wrong, yet it isn't checked as diligently. The same dynamic can be at play when one's work is being weighed by others; papers that confirm previous work and/or readers' biases are accepted with minimal scrutiny, while those that do not are looked at with suspicion. The net result is that there is a natural tendency towards "concordance" in the literature.
It's important to recognize that experimenter bias can push in different directions, depending on the psychology of the individuals involved and the culture of the field. To massively over-generalize based on discussions in a KIPAC-hosted workshop on this subject from some years ago, astronomers tend to be discovery-oriented and tend to overplay work that appears to discover something new and unexpected, or confirm something expected that had not been shown before. In contrast, the most respected results in the dark matter direct detection world are phrased as non-detections, leading to a temptation to clean the data of "suspicious" signals until an impressively tight upper bound is obtained.
The challenge is thus to put into place systems to mitigate experimenter bias without those systems themselves pre-determining the results. A practical solution might look something like this:
- The analysis team is prevented from completing their inference and viewing the results (including any intermediate results that can be used to predict the final result) until they deem their model complete (or, at least, adequate).
- The final inference is done once.
- Post-hoc analysis is then enabled, but with the understanding that it must be clearly identified as such, since experimenter bias is now potentially in play again.
The terms "blinding" and "blinded/unblinded" are frequently used in this context.$^1$
Before "opening the box" for the final inference run, one might use a method like:
Hidden signal box: the subset of data believed most likely to contain the signal is removed
Hidden answer: the numerical values of the parameters being measured are hidden
Adding/removing data (aka "salting"): so that the team don't know whether they have detected a real signal or not
Training on a "pre-scaling" subset: as in cross-validation
You might be wondering what the point of all this is, since the overall workflow hasn't changed: set up and perform an analysis, look at results, and (possibly) do something post-hoc. It's true that none of these methods is a panacea against unconscious experimenter bias (or conscious tampering, for that matter). They have value to the extent that they force us to be skeptical of our own analysis, and therefore slow down and check everything carefully, to a greater extent then we might if everything came out as we expected immediately. This involves doing some qualitatively different things from what we might be used to:
- Organizing analyses in teams, and agreeing to abide by rules
- Temporarily censoring or adjusting datasets while inferences are developed
- Thinking really, really hard about what diagnostics we might be able to look at without informing ourselves as to the results of interest
The perceived finality of opening the box is also beneficial. No one wants to have to admit that they went to all this trouble only to find a major bug after the box was open, so we usually end up checking everything as thoroughly as possible beforehand.
The process may be a pain, but it does seem to increase confidence in the results, both inside and outside the team.
What about small teams?¶
Thinking about experimenter bias in astrophysics and cosmology has been heavily influenced by an influx of particle physicists in recent years. Hence, while it might not be obvious, the strategies above generally implicitly assume that there is a large team involved in working towards some experimental result. But what if we're working in a small group, or alone?
The short answer is that the basic approaches are still sound. We can still
- check our analysis methods for conceptual or code bugs by testing them on mock data of increasing complexity/sophistication, approach that of the real data, rather than on the data itself;
- deliberately avoid looking at intermediate results from which final results of interest can be guessed;
- carefully think about all of the intermediate checks of the data and analysis we can do without violating the above rules, and the order in which we will, finally, start to look at the informative results.
Again, the greatest benefit comes from forcing us to be more deliberate and careful at every step of the analysis, not just upon seeing something unexpected.
Consistency of independent constraints¶
When the same model can be constrained by independent data sets, those constraints might be perfectly consistent with one another. Hooray! We can jointly analyze the data, and get even tighter constraints.
On the other hand, the two sets of constraints could be inconsistent, or in tension with one another. We might conclude that there is a "systematic" error in the modeling of one or both data sets, or an error in the physical model.
How can we quantify the level of consistency between two sets of constraints (posterior PDFs)?
The most common (quick and dirty) quantification of tension between two datasets is the distance between the central values of their likelihoods (or posterior PDFs), in units of "sigma". Here "sigma" is usually taken to be the sum of the two posterior widths, in quadrature, assuming everything is Gaussian (quick/dirty, remember). This would normally be done with 1D or 2D marginalized posteriors, for a subset of parameters where we particularly care about consistency.
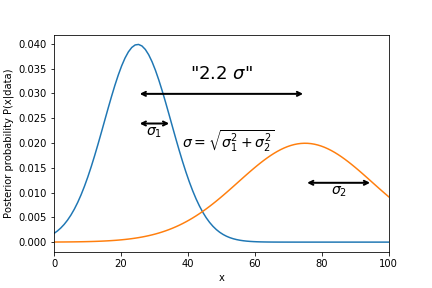
A more mathematically principled approach, which works in any number of dimensions, is to use the Bayesian evidence to quantify the overlap between likelihoods. Consider the following two models:
$H_1$: Both datasets, $d_A$ and $d_B$, were generated from the same global model, with parameters $\theta$.
The evidence for $H_1$ is
$P(\{d_A,d_B\}|H_1) = \int P(d_A|\theta,H_1)P(d_B|\theta,H_1)p(\theta|H_1)\,d\theta$.
This would be computed during a joint fit of both data sets. The alternative is
$H_2$: Each dataset, $d_A$ and $d_B$, was generated from its own local model, with parameters $\theta_A$ and $\theta_B$.
The evidence for $H_2$ is
$P(\{d_A,d_B\}|H_2) = \int P(d_A|\theta_A,H_2)P(d_B|\theta_B,H_2)p(\theta_A|H_2)p(\theta_B|H_2)\,d\theta_A d\theta_B = P(d_A|H_2)P(d_B|H_2)$.
For $H_2$, the evidence is just the product of the evidences computed during separate fits to each data set.
The Bayes factor is therefore
$\frac{P(\{d_A,d_B\}|H_2)}{P(\{d_A,d_B\}|H_1)} = \frac{P(d_A|H_2)P(d_B|H_2)}{P(\{d_A,d_B\}|H_1)}$.
If the inferences of $\theta_A$ and $\theta_B$ under $H_2$ are very different, we would see a large Bayes factor (the combined goodness of fit under $H_2$ would be greater than under $H_1$). Remember that the idea here is just to quantify the agreement or disagreement of the two data sets under $H_1$. If we're seriously considering $H_2$ as an alternative model, then we should assign priors to both before drawing conclusions about which is more probable.
Optional further reading¶
James Berger, "The Bayesian Approach to Discovery" (PHYSTAT 2011)
Kyle Cranmer, "Practical Statistics for the LHC"
Gross & Vitells (2010), "Trial factors for the look elsewhere effect in high energy physics"
MacCoun & Perlmutter (2015), "Hide Results to Seek the Truth"
Klein & Roodman (2005) "Blind Analysis in Nuclear and Particle Physics"
Talks given at the 2017 KIPAC Workshop, "Blind Analysis in High-Stakes Survey Science: When, Why, and How?": http://kipac.github.io/Blinding/
Endnotes¶
Note 1¶
Some commentary on the term "blinding", following discussions in recent years. There are those in the disability community who, reasonably, object to the use of "blind" in the context of voluntarily or intentionally not looking at something, as opposed to being fundamentally unable to do so. Though I'm not aware of any particular outrage about the specific usage we're discussing here, this seems like an argument worth considering when we discuss science. Is the word "blind" itself meaningful and valuable that its use is justified? (My feeling is... probably not, since it isn't even particularly apt; many of the objections to blinding that I've heard rest on the misconception that a blind analysis is one where we don't check that our data make sense nor that our analysis works correctly.) However, I've yet to encounter a clear substitute term for the general approach.
Also problematic is that the term itself is vague enough to have become something of a buzzword, used to present work as superior when it may (and I've seen this) be the complete opposite of "blinded". Hopefully that issue will fade as an understanding of best practices diffuses throughout the field, and we'll converge on language that more precisely describes how experimenter bias was mitigated.