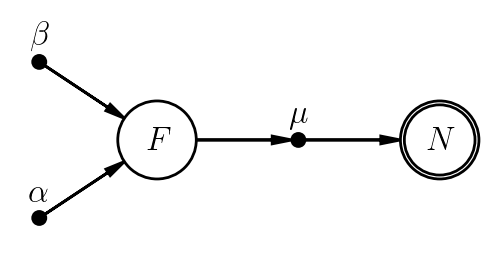
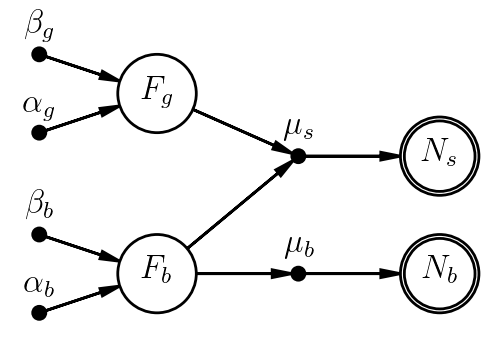
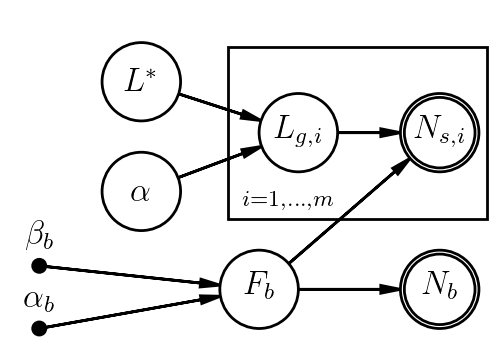
Now let's expand the model to account for the fact that our measurement actually includes counts from both the source (a galaxy, say) and some background. Being good astronomers, we also remembered to take a second measurement of a source-free (background-only) patch of sky.
With subscripts $b$ for background, $g$ for galaxy, $s$ for the science observation that includes both, our model might be
- $F_b \sim \mathrm{Gamma}(\alpha_b,\beta_b)$
- $\mu_b = C_b\,F_b$
- $N_b \sim \mathrm{Poisson}(\mu_b)$
- $F_g \sim \mathrm{Gamma}(\alpha_g,\beta_g)$
- $\mu_s = C_s(F_g+F_b)$
- $N_s \sim \mathrm{Poisson}(\mu_s)$
We'd probably regard $F_b$ and $\mu_b$ as nuisance parameters here - we need to account for our uncertainty in $F_b$, but measuring it isn't the point of the analysis.
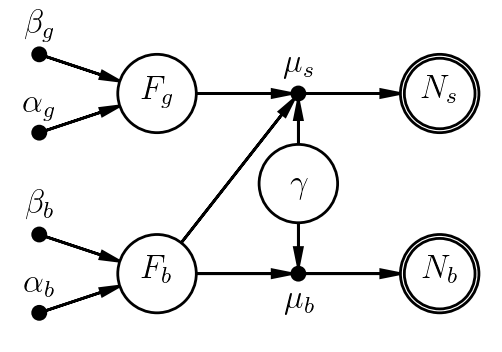
More interestingly, suppose we want to marginalize over systematic uncertainty in the instrument gain, assuming it's the same for both observations. Maybe the instrument team told us it was known to $\sim5\%$. We might introduce a new parameter, $\gamma$, representing the true (unknown) value of the gain relative to its published value (which would be included in $C$ already). Knowing only that $\gamma$ is uncertain at the "$\sim5\%$" level, we'd probably assign it a normal prior. Observe how the model changes:
- $\gamma \sim \mathrm{Normal}(1.0, 0.05)$
- $F_b \sim \mathrm{Gamma}(\alpha_b,\beta_b)$
- $\mu_b = \gamma C_b\,F_b$
- $N_b \sim \mathrm{Poisson}(\mu_b)$
- $F_g \sim \mathrm{Gamma}(\alpha_g,\beta_g)$
- $\mu_s = \gamma C_s(F_g+F_b)$
- $N_s \sim \mathrm{Poisson}(\mu_s)$
In this case, nothing in the data allow us to constrain $\gamma$; its posterior will end up looking like its prior. At the same time, marginalizing over it allows us to propagate the prior uncertainty in $\gamma$ to the posterior distributions of the parameters we care about measureing. This is a common role of nuisance parameters.
As an aside, we'll note that there is a difference, albeit an arguable one, between being complete and being needlessly pedantic. For example, if the prior uncertainty on $\gamma$ were $\sim0.1\%$, and the Poisson uncertainty in the sampling distributions were $\sim10\%$, we would be quite justified in fixing $\gamma=1$, even though it isn't known perfectly.