Tutorial: O-ring Failure Rates Prior to the Challenger Shuttle Loss¶
Coping with missing information¶
In this tutorial, we will use a real data set where unwise interpretation of incomplete data had serious consequences to illustrate how such selection effects could be modeled. You will
- implement and fit a simple model for the probability of O-ring failure as a function of ambient temperature, assuming a complete data set;
- modify the model to account for censoring of the data;
- compare the inferences form the complete data with those of the censored data with "vague" and "specific" prior information.
from os import getcwd
from os.path import exists as file_exists
from yaml import safe_load
import numpy as np
import scipy.stats as st
import matplotlib.pyplot as plt
%matplotlib inline
import emcee
import incredible as cr
from pygtc import plotGTC
thisTutorial = 'missing_data'
if getcwd() == '/content':
# assume we are in Colab, and the user's data directory is linked to their drive/Physics267_data
from google.colab import drive
drive.mount('/content/drive')
datapath = '/content/drive/MyDrive/Physics267_data/' + thisTutorial + '/'
else:
# assume we are running locally somewhere and have the data under ./data/
datapath = 'data/'
Background¶
On January 28, 1986, the Space Shuttle Challenger was destroyed in an explosion during launch. The cause was eventually found to be the failure of an O-ring seal that normally prevents hot gas from leaking between two segments of the solid rocket motors during their burn. The ambient atmospheric temperature of just 36 degrees Fahrenheit, significantly colder than any previous launch, was determined to be a significant factor in the failure.
A relevant excerpt from the Report of the Presidential Commission on the Space Shuttle Challenger Accident reads:
Temperature Effects¶
The record of the fateful series of NASA and Thiokol meetings, telephone conferences, notes, and facsimile transmissions on January 27th, the night before the launch of flight 51L, shows that only limited consideration was given to the past history of O-ring damage in terms of temperature. The managers compared as a function of temperature the flights for which thermal distress of O-rings had been observed-not the frequency of occurrence based on all flights (Figure 6). In such a comparison, there is nothing irregular in the distribution of O-ring "distress" over the spectrum of joint temperatures at launch between 53 degrees Fahrenheit and 75 degrees Fahrenheit. When the entire history of flight experience is considered, including"normal" flights with no erosion or blow-by, the comparison is substantially different (Figure 7).
This comparison of flight history indicates that only three incidents of O-ring thermal distress occurred out of twenty flights with O-ring temperatures at 66 degrees Fahrenheit or above, whereas, all four flights with O-ring temperatures at 63 degrees Fahrenheit or below experienced O-ring thermal distress.
Consideration of the entire launch temperature history indicates that the probability of O-ring distress is increased to almost a certainty if the temperature of the joint is less than 65.
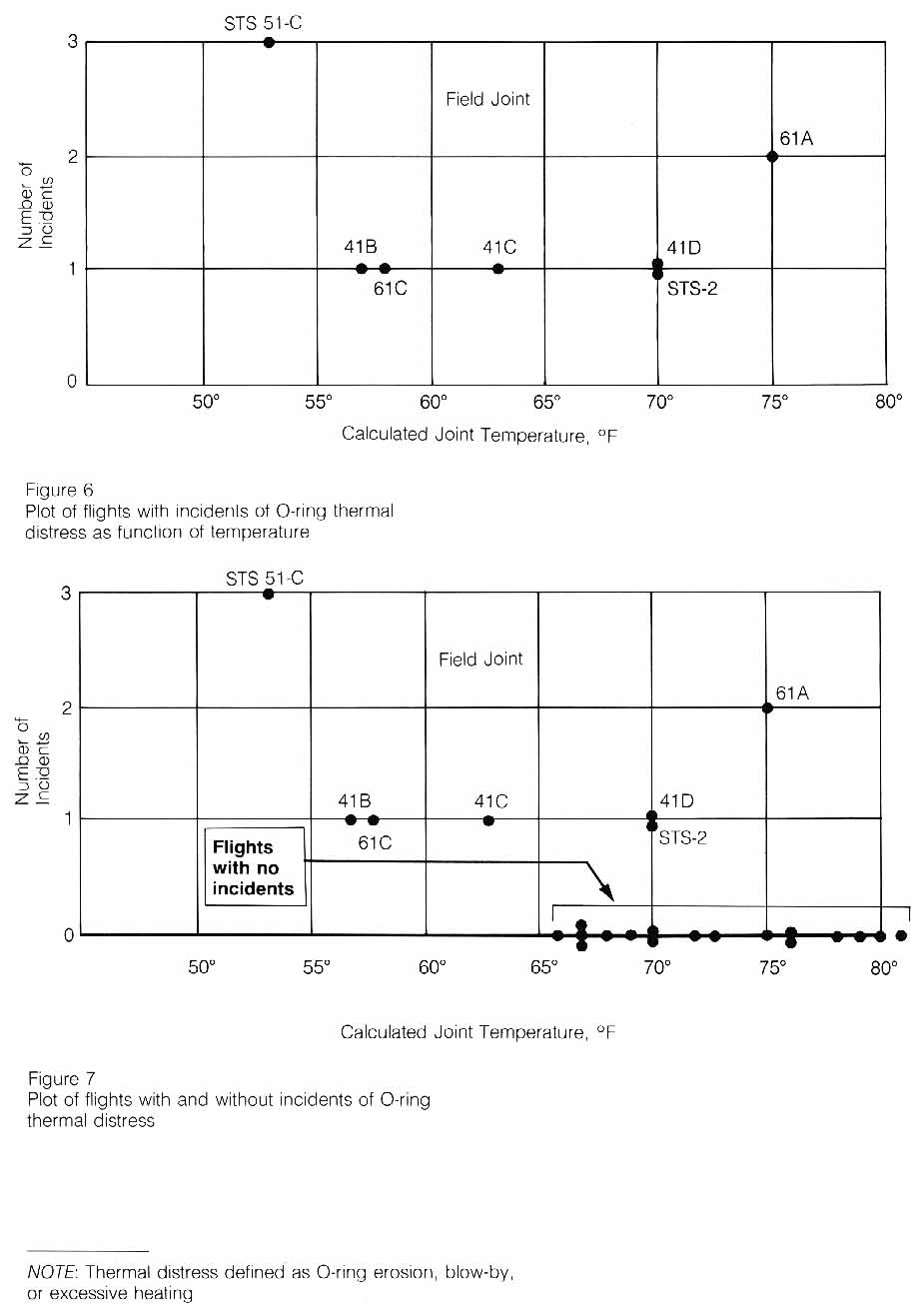 |
The data above show the number of incidences of O-ring damage found in previous missions as a function of the temperature at launch.
For this notebook, we will simplify the data for each launch from integer (how many incidents of O-ring damage) to boolean (was there any damage, or not). The temperatures corresponding to "failure" (any incidents) and "success" (no incidents) are:
failure_temps = np.array([53., 56., 57., 63., 70., 70., 75.])
success_temps = np.array([66., 67., 67., 67., 68., 69., 70., 70., 72., 73., 75., 76., 76., 78., 79., 80., 81.])
The above cell is provided for convenience, if you want to see how this analysis works out for the real pre-Challenger data (it is also used in the public solutions). As usual, we also provide enrolled students with their own realistic but randomly generated data. Lucky you! (Note: it's consequently possible that you won't reach the same conclusions as others and/or the public solutions. Some of the commentary below may not be applicable.)
data = safe_load(open(datapath+'data.yaml', 'r').read())
failure_temps = np.array(data['failure'])
success_temps = np.array(data['success'])
print("Failure temperatures:", failure_temps)
print("Success temperatures:", success_temps)
Failure temperatures: [53. 56. 57. 63. 70. 70. 75.] Success temperatures: [66. 67. 67. 67. 68. 69. 70. 70. 72. 73. 75. 76. 76. 78. 79. 80. 81.]
To get a more visual feel, below we plot the data similarly to how they are shown above (a small amount of vertical jitter is included so that points don't cover one another completely).
plt.rcParams['figure.figsize'] = (6, 4)
plt.plot(success_temps, st.norm.rvs(success_temps*0.0, 0.05), 'o', label='Successes');
plt.plot(failure_temps, st.norm.rvs(failure_temps*0.0+1.0, 0.05), 'o', label='Failures');
plt.xlim(45,85); plt.ylim(-1,2); plt.xlabel('Temperature (F)'); plt.yticks([]); plt.legend();

1. Defining a model¶
Before worrying about missing data, let's define a model that we might want to fit to the complete data. We're interested in whether the probability of having zero O-ring incidents (or non-zero incidents, conversely) is a function of temperature. One possible parametrization that allows this is the logistic function, which squeezes the real line onto the range (0,1).
For reasons that may be clear later, I suggest defining the model in terms of the probability of success (zero incidents)
$P_\mathrm{success}(T|T_0,\beta,P_\mathrm{cold},P_\mathrm{hot}) = P_\mathrm{cold} + \frac{P_\mathrm{hot} - P_\mathrm{cold}}{1 + e^{-\beta(T-T_0)}}$,
with parameters $T_0$ and $\beta$ respectively determining the center and width of the logistic function, and $P_\mathrm{cold}$ and $P_\mathrm{hot}$ determine the probabilities of success at very low and high temperatures (which need not be 0 or 1).
As we'll see in a moment, a model like this provides a smooth, linear-ish transition between two extreme values, without imposing the strong prior that $P_\mathrm{success}$ must drop to zero at some point, for example.
1a. Implement this function and have a look¶
def P_success(T, T0, beta, Pcold, Phot):
"""
Evaluate Psuccess as given above, as a function of T, for parameters T0, beta, Pcold, Phot.
"""
Below we plot the function for a few different parameter values. If you've never worked with the logistic function (or a similar sigmoid function) before, this will give you an idea of how flexible it is and isn't.
plt.rcParams['figure.figsize'] = (6, 4)
T_axis = np.arange(32., 100.)
plt.plot(T_axis, P_success(T_axis, 70.0, 0.3, 0.0, 1.0));
plt.plot(T_axis, P_success(T_axis, 65.0, 0.1, 0.4, 0.9));
plt.plot(T_axis, P_success(T_axis, 45.0, 1.0, 0.1, 0.5));
plt.plot(T_axis, P_success(T_axis, 80.0, 0.5, 0.9, 0.2));
plt.xlabel('temperature (F)');
plt.ylabel('probability of a clean launch');

1b. PGM and priors¶
Given the definition of the data and model above, draw the PGM for this problem, write down the corresponding probability expressions, and write down the likelihood (all assuming we have the complete data set).
Space for your PGM etc.
Choosing priors is a little tricky because we're interested in the model's predictions at $T=36$ degrees F, which is an extrapolation even for the complete data set.
We'd like our model to be consistent with no trend a priori - that way we can see relatively straightforwardly whether the data require there to be a trend. A pleasingly symmetric way to allow this is to put identical, independent priors on $P_\mathrm{cold}$ and $P_\mathrm{hot}$, in particular including the possibility that $P_\mathrm{cold} > P_\mathrm{hot}$ even though that isn't what we're looking for. Thus, a solution with $P_\mathrm{cold}=P_\mathrm{hot}$, i.e. no trend, is perfectly allowed.
Our temperature data are given in integer degrees, so it doesn't make sense to allow values of $\beta$ too much greater than 1, since the data would not resolve such a sudden change (which would increasingly make $P_\mathrm{success}$ resemble a step function). By definition, $\beta>0$ (it's a "rate" parameter).
In principle, we might allow $T_0$ to take any value. But, arguably, the most sensible thing we can do with such limited information is test whether there is evidence for a trend in the probability of O-ring failure within the range of the available data (or, a little more casually, the range of the figure from the report, above). Given the flexibility already provided by the choices above, there's little obvious benefit to allowing $T_0$ to vary more than this.
As usual, note: in class we will discuss this more and agree on a common set of priors that everyone should use. Once we have done so, implement the log-prior function below.
def ln_prior(T0, beta, Pcold, Phot):
"""
Return the log-prior density for parameters T0, beta, Pcold, Phot
"""
Let's make sure the parameter space that definitely should be excluded by the prior is:
assert ln_prior(-70.0, 0.3, 0.0, 1.0) == -np.inf
assert ln_prior(70.0, -0.3, 0.0, 1.0) == -np.inf
assert ln_prior(70.0, 0.3, -0.1, 1.0) == -np.inf
assert ln_prior(70.0, 0.3, 1.1, 1.0) == -np.inf
assert ln_prior(70.0, 0.3, 0.0, -1.0) == -np.inf
assert ln_prior(70.0, 0.3, 0.0, 2.0) == -np.inf
Finally, let's check what your prior implies for the failure probability at a temperature of 36 degrees. This is a good idea whenever we are interesting in inferring a quantity whose prior is "indirect" (usually because it is not itself a sampled parameter). We'll need a function that samples our free parameters from the prior:
def prior_sample():
""" Return a dictionary with keys T0, beta, Pcold, Phot containing a random draw from the prior """
Have a look:
plt.rcParams['figure.figsize'] = (5,3)
prior_samples = [1.0 - P_success(T=36., **prior_sample()) for i in range(5000)]
plt.hist(prior_samples, density=True); plt.xlabel('Prior probability of failure at 36F');

Is this distribution as expected based on the priors for the explicit model parameters? Any surprises?
I_have_thought_about_this_and_it_makes_sense = False # change to True when true
assert I_have_thought_about_this_and_it_makes_sense
1c. Model fitting code¶
Since the point of this tutorial is model design rather than carrying out a fit, a bunch of code is given below. Naturally, you should ensure that you understand what the code is doing, even though there's nothing to add.
Here we follow a similar, though simpler, approach to the object oriented code used in the model evaluation notebook, since the models we'll compare all have the same set of free parameters. The Model object will take log-prior and log-likelihood functions as inputs in its constructor (instead of deriving new classes corresponding to different likelihoods), and will deal with the computational aspects of fitting the parameters. It will also provide a posterior prediction for the thing we actually care about, the failure probability at a given temperature. To do this, we need to marginalize over the model parameters; that is, we compute the posterior-weighted average of $1-P_\mathrm{success}$, at some temperature of interest, over the parameter space.
class Model:
def __init__(self, log_prior, log_likelihood):
self.log_prior = log_prior
self.log_likelihood = log_likelihood
self.param_names = ['T0', 'beta', 'Pcold', 'Phot']
self.param_labels = [r'$T_0$', r'$\beta$', r'$P_\mathrm{cold}$', r'$P_\mathrm{hot}$']
self.sampler = None
self.samples = None
def log_posterior(self, pvec=None, **params):
'''
Our usual log-posterior function, able to take a vector argument to satisfy emcee
'''
if pvec is not None:
pdict = {k:pvec[i] for i,k in enumerate(self.param_names)}
return self.log_posterior(**pdict)
lnp = self.log_prior(**params)
if lnp != -np.inf:
lnp += self.log_likelihood(**params)
return lnp
def sample_posterior(self, nwalkers=8, nsteps=10000, guess=[65.0, 0.1, 0.25, 0.75], threads=1):
# use emcee to sample the posterior
npars = len(self.param_names)
self.sampler = emcee.EnsembleSampler(nwalkers, npars, self.log_posterior, threads=threads)
start = np.array([np.array(guess)*(1.0 + 0.01*np.random.randn(npars)) for j in range(nwalkers)])
self.sampler.run_mcmc(start, nsteps)
plt.rcParams['figure.figsize'] = (16.0, 3.0*npars)
fig, ax = plt.subplots(npars, 1);
cr.plot_traces(self.sampler.chain[:min(8,nwalkers),:,:], ax, labels=self.param_labels);
def check_chains(self, burn=500, maxlag=500):
'''
Ignoring `burn` samples from the front of each chain, compute convergence criteria and
effective number of samples.
'''
nwalk, nsteps, npars = self.sampler.chain.shape
if burn < 1 or burn >= nsteps:
return
tmp_samples = [self.sampler.chain[i,burn:,:] for i in range(nwalk)]
R = cr.GelmanRubinR(tmp_samples)
print('R =', R)
neff = cr.effective_samples(tmp_samples, maxlag=maxlag, throw=True)
print('neff =', neff)
print('NB: Since walkers are not independent, these will be optimistic!')
return R,neff
def remove_burnin(self, burn=500):
'''
Remove `burn` samples from the front of each chain, and concatenate.
Store the result in self.samples.
'''
nwalk, nsteps, npars = self.sampler.chain.shape
if burn < 1 or burn >= nsteps:
return
self.samples = self.sampler.chain[:,burn:,:].reshape(nwalk*(nsteps-burn), npars)
def posterior_prediction_Pfailure(self, temperatures=np.arange(30., 85.), probs=[0.5, 0.16, 0.84]):
'''
For the given temperatures, compute and store quantiles of the posterior predictive distribution for O-ring failure.
By default, return the median and a 68% credible interval (defined via quantiles).
'''
Pfail = np.array([1.0-P_success(T, self.samples[:,0], self.samples[:,1], self.samples[:,2], self.samples[:,3]) for T in temperatures])
res = {'T':temperatures, 'p':[str(p) for p in probs]}
for p in probs:
res[str(p)] = np.quantile(Pfail, p, axis=1)
self.post_failure = res
def plot_Pfailure(self, ax, color, label):
'''
Plot summaries of the posterior predictive distribution for O-ring failure.
Show the center as a solid line and credible interval(s) bounded by dashed lines.
'''
ax.plot(self.post_failure['T'], self.post_failure[self.post_failure['p'][0]], color+'-', label=label)
n = len(self.post_failure['p'])
if n > 1:
for j in range(1,n):
ax.plot(self.post_failure['T'], self.post_failure[self.post_failure['p'][j]], color+'--')
ax.set_xlabel('T (F)');
ax.set_ylabel(r'$P_\mathrm{failure}(T)$');
ax.legend();
def post1d_Pfailure(self, T):
self.whist = cr.whist(1.0-P_success(T, *self.samples.T))
2. Solution for complete data¶
First, let's see what the solution looks like when there are no missing data. Complete the likelihood function appropriate for a complete data set below.
def ln_like_complete(T0, beta, Pcold, Phot):
"""
Return the log-likelihood corresponding to a complete data set
(Go ahead and access `failure_temps' and `success_temps' from global scope, even though this is not good programming practice)
"""
Now we put the Model code to work. The defaults below should work well enough, but do keep an eye the usual basic diagnostics as provided below, and make any necessary changes.
guess = [65.0, 0.1, 0.25, 0.75] # starting position
burn = 1000 # burn-in
maxlag = 1500 # max lag for Neffective estimate
nsteps = 15000
First we instantiate the model...
complete_model = Model(ln_prior, ln_like_complete)
... and run the fit. Note that the parameters are not likely to be individually well contrained by the data, compared with the prior. We don't necessarily care about this - the important question is what the posterior predictive distribution for the probability of failure at a given temperature looks like. (We do, or course, need the chains to be converged and adequately sampled, however.)
%%time
complete_model.sample_posterior(nwalkers=8, nsteps=nsteps, guess=guess)
CPU times: user 11.1 s, sys: 54.6 ms, total: 11.2 s Wall time: 11.2 s

Check the usual diagnostics (note: autocorrection is likely to be relatively high):
R,neff = complete_model.check_chains(burn=burn, maxlag=maxlag)
assert np.all(R < 1.05)
assert np.all(neff > 400)
R = [1.00425898 1.00280167 1.0091491 1.00267955]
neff = [ 726.51284986 1218.01819689 723.05536844 1183.78155128] NB: Since walkers are not independent, these will be optimistic!
Finally, remove burn-in and plot the marginal posteriors:
complete_model.remove_burnin(burn=burn)
plotGTC(complete_model.samples, paramNames=complete_model.param_labels,
figureSize=6, customLabelFont={'size':12}, customTickFont={'size':12}, customLegendFont={'size':16});

There's a good chance that the chains and posterior look considerably uglier than you're used to in this course. (See comments in earlier notes about the difference between convergence and having tight constraints.) Again, this is a situation where we are less concerned with constraints on individual parameters than with predictions for the predicted failure probability as a function of temperature. So let's visualize that. The solid and dashed lines below-left show the posterior-predictive median and and percentile-based 68% credible interval for $P_\mathrm{failure} = 1 - P_\mathrm{success}$ at each temperature. The right panel shows the posterior for $P_\mathrm{failure}$ at a temperature of 36 F specifically. Note that this is a case where the median and mode of the posterior are quite different.
complete_model.posterior_prediction_Pfailure()
complete_model.post1d_Pfailure(36.)
plt.rcParams['figure.figsize'] = (12., 4.)
fig, ax = plt.subplots(1, 2);
complete_model.plot_Pfailure(ax[0], 'C0', 'complete')
ax[1].plot(complete_model.whist['x'], complete_model.whist['density']);
ax[1].set_xlabel(r'$P_\mathrm{failure}(T=36$ F$)$'); ax[1].set_ylabel('posterior density');

Does this outcome make sense compared with inspection of the data and the prior? Does, as the report concludes, "the probability of O-ring distress [increase] to almost a certainty" at temperatures below 65F based on these data?
I_have_thought_about_these_questions = False # change to True when true
assert I_have_thought_about_these_questions
3. Censored (but somewhat informed) success temperatures¶
Imagine we are in a slightly better situation than that shown in the top panel of Figure 6 from the report. Namely, we are given
- the temperatures of launches where there were O-ring failures (
failure_tempsabove), - the number of launches with no failures,
- a range of temperatures containing the successful launches, but not the precise temperatures of each.
For (3), we'll just use the actual min and max of success_temps. In the next section, we'll look at the results with even less information about the success temperatures.
success_Tmin = np.min(success_temps)
success_Tmax = np.max(success_temps)
Nsuccess = len(success_temps)
We will now discard success_temps entirely, to remove any temptation.
del success_temps
3a. Censored model definition¶
Adjust your PGM and expression for the likelihood to reflect our ignorance of the temperatures of successful launches. Since they are now unknown and not dictated by anything in our previous model, the success temperatures will need a prior distribution, which we will take to be uniform over the range [success_Tmin, success_Tmax].
Space for your censored PGM, etc.
We will need to marginalize over the parameters corresponding with the success temperatures, since they are no longer fixed data. We could do so by MCMC sampling them, but in this case direct integration is simpler. To be explicit, if $\theta$ abbreviates the 4 model parameters we had previously and $\phi$ stands for all the success temperatures, this marginalization looks like
$p(\theta|\mathrm{data}) = \int d\phi \, p(\theta,\phi|\mathrm{data}) \propto p(\theta) \int d\phi \, p(\phi) \, p(\mathrm{data}|\theta,\phi) \equiv p(\theta) \, p(\mathrm{data}|\theta)$.
As the last equivalence indicates, the integral of the sampling distribution, $p(\mathrm{data}|\theta,\phi)$, over the prior for the success temperatures will function as our marginalized likelihood.
The reason for marginalizing this way is that, for our particular definition of $P_\mathrm{success}$ and a uniform prior $p(\phi)$, the integral is analytic (see Wikipedia). Take advantage of this when implementing the marginalized likelihood function below.
def ln_like_censored(T0, beta, Pcold, Phot):
"""
Return the log-likelihood for the case of censored success temperatures.
This prototype assumes the success temperatures will be marginalized over within this function; otherwise
they would need to be additional parameters to be sampled.
(Go ahead and access `failure_temps', `Nsuccess', `success_Tmin' and `success_Tmax' from global scope, even though this is poor programming practice)
"""
3b. Censored model fit¶
We can now carry out the usual steps. Again, the choices made below will probably work, but change them if need be.
guess = [65.0, 0.1, 0.25, 0.75] # starting position
burn = 1000 # burn-in
maxlag = 1500 # max lag for Neffective estimate
nsteps = 15000
censored_model = Model(ln_prior, ln_like_censored)
%%time
censored_model.sample_posterior(nwalkers=8, nsteps=nsteps, guess=guess)
CPU times: user 10.8 s, sys: 59.4 ms, total: 10.9 s Wall time: 11.1 s

R,neff = censored_model.check_chains(burn=burn, maxlag=maxlag)
assert np.all(R < 1.05)
assert np.all(neff > 400)
R = [1.00191858 1.00457386 1.00214692 1.00012395]
neff = [1185.11198257 1046.53614751 1135.71056118 1171.0699351 ] NB: Since walkers are not independent, these will be optimistic!
censored_model.remove_burnin(burn=burn)
plotGTC([complete_model.samples, censored_model.samples], paramNames=complete_model.param_labels,
chainLabels=['complete', 'censored'],
figureSize=6, customLabelFont={'size':12}, customTickFont={'size':12}, customLegendFont={'size':16});

Now let's compare the posterior predictions to the previous result.
censored_model.posterior_prediction_Pfailure()
censored_model.post1d_Pfailure(36.)
plt.rcParams['figure.figsize'] = (12., 4.)
fig, ax = plt.subplots(1, 2);
complete_model.plot_Pfailure(ax[0], 'C0', 'complete')
censored_model.plot_Pfailure(ax[0], 'C1', 'censored')
ax[1].plot(complete_model.whist['x'], complete_model.whist['density']);
ax[1].plot(censored_model.whist['x'], censored_model.whist['density']);
ax[1].set_xlabel(r'$P_\mathrm{failure}(T=36$ F$)$'); ax[1].set_ylabel('posterior density');

Questions to ponder:
- Does your censored model manage to make consistent predictions to the model fitted to the complete data?
- If there are clear differences, do they make sense in light of what information has been hidden?
- Is there still evidence for a temperature-dependent failure rate?
- Does, as the report concludes, "the probability of O-ring distress [increase] to almost a certainty" at temperatures below 65F based on these (censored) data?
I_have_pondered_them = False # change to True when true
assert I_have_pondered_them
4. Censored (less informed) success temperatures¶
As a point of comparison, let's fit a model in which the temperature range for the censored (success) data is much less well constrained. This is arguably more analogous to what we might do by eye if presented with the first figure in this notebook, knowing that successful launches were absent from the figure, but without the context that those launches has all taken place in warm weather.
In particular, let's take the prior on the success temperatures to be uniform over the range shown in the figure. We followed poor practice by defining success_Tmin and success_Tmax at global scope earlier and then using them from global scope in ln_like_censored, and will continue to do so by reusing those variables below. The upshot is that all of the functions you've already completed should work as-is, as long as the notebook is never run out of order.
success_Tmin = 45.0
success_Tmax = 80.0
Once again, we expect that the defaults below will work, but be alert and change them if needed.
guess = [65.0, 0.1, 0.25, 0.75] # starting position
burn = 1000 # burn-in
maxlag = 1500 # max lag for Neffective estimate
nsteps = 15000
We proceed just as before, reusing ln_like_censored, since it looks up success_Tmin and success_Tmax at global scope.
verycensored_model = Model(ln_prior, ln_like_censored)
%%time
verycensored_model.sample_posterior(nwalkers=8, nsteps=nsteps, guess=guess)
CPU times: user 10.1 s, sys: 36.7 ms, total: 10.1 s Wall time: 10.2 s

R,neff = verycensored_model.check_chains(burn=burn, maxlag=maxlag)
assert np.all(R < 1.05)
assert np.all(neff > 400)
R = [1.00177103 1.00534173 1.00994032 1.00358337]
neff = [562.09379088 874.29490823 639.40908906 865.3949379 ] NB: Since walkers are not independent, these will be optimistic!
verycensored_model.remove_burnin(burn=burn)
plotGTC([complete_model.samples, censored_model.samples, verycensored_model.samples], paramNames=complete_model.param_labels,
chainLabels=['complete', 'censored', 'very censored'],
figureSize=6, customLabelFont={'size':12}, customTickFont={'size':12}, customLegendFont={'size':16});

This seems like it will lead to somewhat different posterior predictions. Let's check.
verycensored_model.posterior_prediction_Pfailure()
verycensored_model.post1d_Pfailure(36.)
plt.rcParams['figure.figsize'] = (12., 4.)
fig, ax = plt.subplots(1, 2);
complete_model.plot_Pfailure(ax[0], 'C0', 'complete')
censored_model.plot_Pfailure(ax[0], 'C1', 'censored')
verycensored_model.plot_Pfailure(ax[0], 'C2', 'very censored')
ax[1].plot(complete_model.whist['x'], complete_model.whist['density']);
ax[1].plot(censored_model.whist['x'], censored_model.whist['density']);
ax[1].plot(verycensored_model.whist['x'], verycensored_model.whist['density']);
ax[1].set_xlabel(r'$P_\mathrm{failure}(T=36$ F$)$'); ax[1].set_ylabel('posterior density');

Ruminate upon the same questions as before:
- Does this more censored model manage to make consistent predictions to the model fitted to the complete data and/or the less censored data?
- If there are clear differences, do they make sense in light of what information has been hidden?
- Is there still evidence for a temperature-dependent failure rate?
- Does, as the report concludes, "the probability of O-ring distress [increase] to almost a certainty" at temperatures below 65F based on these (very censored) data?
I_have_ruminated_sufficiently = False # change to True when true
assert I_have_ruminated_sufficiently
Parting thoughts¶
We approached this problem backwards in a sense, knowing the answer provided by the complete data set, and progressively hiding information to find out what it would take to avoid the conclusion that O-ring failure probability increases significantly at lower temperatures. One could argue about whether the simplified model we fit above is ideal, but (we promise) it isn't contrived to reach the following conclusion: even without knowing the specific temperatures of successful launches, it's hard to avoid concluding that a low-temperature launch is less likely to succeed. One also needs to ignore the much less specific (and presumably widely known) fact that every incident-free launch had occured in much warmer weather than Challenger, while, conversely, every launch in remotely chilly weather had had an O-ring incident. This is, effectively, the distinction between the less and more censored versions of the data that you analyzed above.
In this notebook, we didn't look at the case of truncated data, where the number of missing points is itself unknown. Something to think about: how would our results above change if we didn't know the number of successful launches, in addition to not knowing their temperatures?