Background¶
On January 28, 1986, the Space Shuttle Challenger was destroyed in an explosion during launch. The cause was eventually found to be the failure of an O-ring seal that normally prevents hot gas from leaking between two segments of the solid rocket motors during their burn. The ambient atmospheric temperature of just 36 degrees Fahrenheit, significantly colder than any previous launch, was determined to be a significant factor in the failure.
A relevant excerpt from the Report of the Presidential Commission on the Space Shuttle Challenger Accident reads:
Temperature Effects¶
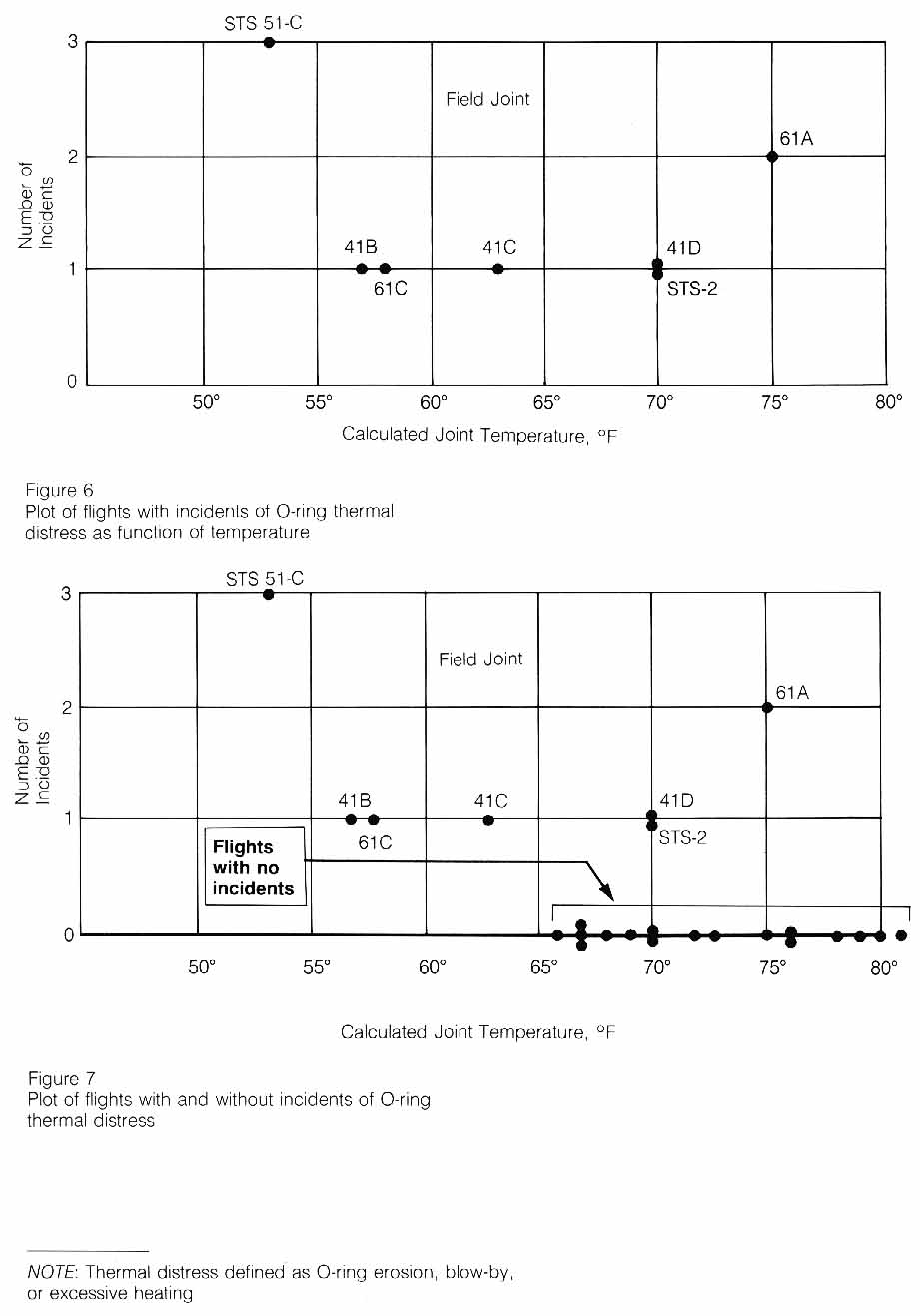
The record of the fateful series of NASA and Thiokol meetings, telephone conferences, notes, and facsimile transmissions on January 27th, the night before the launch of flight 51L, shows that only limited consideration was given to the past history of O-ring damage in terms of temperature. The managers compared as a function of temperature the flights for which thermal distress of O-rings had been observed-not the frequency of occurrence based on all flights (Figure 6). In such a comparison, there is nothing irregular in the distribution of O-ring "distress" over the spectrum of joint temperatures at launch between 53 degrees Fahrenheit and 75 degrees Fahrenheit. When the entire history of flight experience is considered, including"normal" flights with no erosion or blow-by, the comparison is substantially different (Figure 7).
This comparison of flight history indicates that only three incidents of O-ring thermal distress occurred out of twenty flights with O-ring temperatures at 66 degrees Fahrenheit or above, whereas, all four flights with O-ring temperatures at 63 degrees Fahrenheit or below experienced O-ring thermal distress.
Consideration of the entire launch temperature history indicates that the probability of O-ring distress is increased to almost a certainty if the temperature of the joint is less than 65.
 |