Tutorial: Microlensing Lightcurve¶
In this notebook, we'll be looking at data from the Optical Gravitational Lensing Experiment (OGLE), which monitors stars in our galaxy in the hopes of detecting gravitational microlensing events that occur when a compact mass (e.g. a fainter star) passes in front of the monitored star. Data are available through the OGLE Early Warning System, which can be fun to browse through.
We will use this exercise as an excuse to work through calculation of the evidence using nested sampling, with the idea that we will use it for detection - that is, we will compare a model where there is a microlensing event with one where there is not. This is a little hacky, since the lightcurves available have already been selected to contain lensing events (using a different method), but we'll do it anyway. This is also a case where everyone will be using real rather than simulated data, with all of the interesting features that sometimes implies.
You will
- perform a standard MCMC fit of a microlensing model, as a baseline;
- use nested sampling to find constraints on the model parameters and compute the evidence;
- perform nested sampling on a lensing-free (i.e. constant) model, and compare the posterior probability of the two models.
# !pip install dynesty emcee incredible pygtc
from os import getcwd
from os.path import exists as file_exists
from yaml import safe_load
import numpy as np
from scipy.optimize import minimize
import scipy.stats as st
import matplotlib.pyplot as plt
%matplotlib inline
import dynesty
from dynesty import plotting as dyplot
import emcee
import incredible as cr
from pygtc import plotGTC
thisTutorial = 'microlensing'
if getcwd() == '/content':
# assume we are in Colab, and the user's data directory is linked to their drive/Physics267_data
from google.colab import drive
drive.mount('/content/drive')
datapath = '/content/drive/MyDrive/Physics267_data/' + thisTutorial + '/'
else:
# assume we are running locally somewhere and have the data under ./data/
datapath = 'data/'
Data¶
Let's first read in your data and take a look at it. The data are provided in the form of a simple table.
dat = np.loadtxt(datapath+'phot.dat.gz')
dat.shape
As described on the OGLE page, the columns of this text file are
Hel.JD, I magnitude, magnitude error, seeing estimation (in pixels - 0.26"/pixel), sky level
Heliocentric Julian Date. This is time, measured in days, since a fixed reference. The "heliocentric" part means that it has been corrected to the reference frame of the Sun, i.e. the few minutes of light travel time that would affect photon arrivals at different parts of the Earth's year have been subtracted off.
Measurements of magnitude in the $I$ band (a near infrared band). If you're not already familiar (lucky you): astronomical apparent magnitude, relative to a given reference source, is given by the relationship $m = m_\mathrm{ref} - 2.5\,\log_{10}\left(\frac{F}{F_\mathrm{ref}}\right)$, where $F$ is flux. So apparent magnitude is a logarithmic measure of flux, with the very annoying bonus feature that higher fluxes correspond to lower magnitudes.
Measurement uncertainty on the $I$ magnitude, defined in some unspecified way (digging through papers might elucidate this).
Some estimate of the seeing (the width of the PSF) during the observation. (Since these are ground-based observatios, the PSF varies with time, depending on the weather.)
An estimate of the brightness of the sky (the primary background) in $I$ band during the observation.
Let's extract the first 3 columns. We'll ignore the others, since the seeing and sky background have been accounted for already in the magnitude measurements, according to the OGLE site.
As you can be inspection or in any of the lightcurve figures on the OGLE website, HJD is a huge number. Let's follow their lead by subtracting a big constant from it, so that we're left with a number of order only thousands. We'll also organize the useful columns of the table into a dictionary for later convenience.
data = {'t':dat[:,0], # date
'I':dat[:,1], # I magnitude
'Ierr':dat[:,2], # I magnitude uncertainty
't0':2450000.} # reference time
data['t'] -= data['t0']
This should produce a plot similar to those shown on the webpage for each event. Note the inverted Y axis, such that higher means brighter (smaller $I$).
plt.rcParams['figure.figsize'] = (20.0, 4.0)
plt.errorbar(data['t'], data['I'], yerr=data['Ierr'], fmt='.');
plt.xlabel('HJD - '+str(data['t0']));
plt.ylabel('I magnitude');
plt.gca().invert_yaxis();
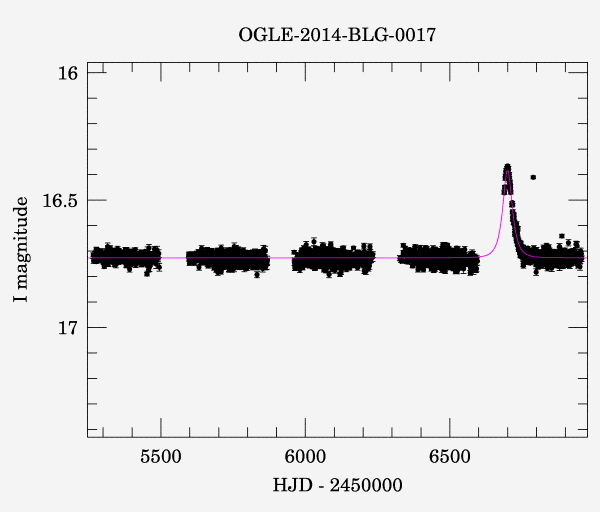
Details vary, but you should see a lightcurve with some gaps in it, and some indication of a transient increase (usually these show up near the end, for some reason). The points tend to be jumbled together, but it's probably clear that there's a bit of variation in the measurements, even when the lightcurve is essentially constant. You might also see one or a few points that are scattered very far away from all of their neighbors. That is, some points seem unlikely to be explicable by a smooth model with added noise, microlensing or not. If you're not sure you can see any of these in your data, consider the lightcurve below, which is used in the public solutions.
 |
So, assuming there are such outliers, what are we going to do about them?
- The purist (and purest) approach would be to leave the data alone and adjust the model such that it can produce occasional outliers like those seen. That is, the sampling distribution would need to have heavy tails or be a mixture model of some kind, and we would learn something about how common and how extreme the outliers are. The downside to this is that we might spend a lot of time doing model comparison to come up with something that fits the data, and if we don't have many outliers than we probably won't learn very much about them. We'll have just gone to great effort to remove the influence of a few points that we could probably have identified and deleted by eye unamiguously enough.
- The opposite approach would correspond to saying something like: I know that this point or points is obviously wrong, and I will just remove it. You can think of this as the previous strategy, but with a really strong prior that bypasses the modeling process. There are clearly objections that one could make to this on the basis that it is so ad hoc/subjective/not independently reproducible.
You can imagine other approaches, e.g. iteratively fitting and throwing away points that are "too far away" (as in sigma clipping), as living somewhere between these two extremes.
Because we will normally have plenty of data covering the time that the star being observed is essentially constant, I suggest that the practical option is to leave in any weird looking data points, even if we don't quite belive that our model sampling distribution is a perfect description... except for any that are really, egregiously, unambiguously, in no uncertain terms and without argument unrepresentative of the models we're fitting. Like the one at time ~6800 in the OGLE figure above.
Programatically, one way to implement this is by creating a mask. This will be a boolean array of the same length as the data, with False meaning we should use a given point and True meaning it should be ignored (note that the true/false convention varies, but this is consistent with how we'll use the mask array below). Then we just need a logical expression that isolates the points we want to keep. For example, I used ~np.logical_and(data['t'] > 6700, data['I'] < 16.6) for 2014-BLG-0017, above. (The ~ is a logical NOT.) Define a mask below; if you don't want to remove any data, it's fine for the mask to be all True values.
# bad_data = ...
# YOUR CODE HERE
raise NotImplementedError()
Let's plot your data again, showing the points you decided to mask as big red diamonds:
plt.rcParams['figure.figsize'] = (20.0, 4.0)
plt.errorbar(data['t'][~bad_data], data['I'][~bad_data], yerr=data['Ierr'][~bad_data], fmt='.');
plt.errorbar(data['t'][bad_data], data['I'][bad_data], yerr=data['Ierr'][bad_data], fmt='rD');
plt.xlabel('HJD - '+str(data['t0']));
plt.ylabel('I magnitude');
plt.gca().invert_yaxis();
There are applications where we would want to keep the original data arrays as they are and use the mask to limit our likelihood calculations to the desired subset. Image analysis is one example, since we generally want the images to remain as 2D arrays, even if there are specific pixels we should ignore. However, in this case, it seems harmless to simply redefine the arrays in data to exclude the points we want to remove.
for k in ['I', 'Ierr', 't']:
data[k] = data[k][~bad_data]
# below is in principle a more elegant option, but it slowed down the notebook by a factor >2, so no
#data[k] = np.ma.masked_array(data=data[k], mask=bad_data)
Model¶
An excellent resource for gravitational lensing background (among other things) is Peter Schneider's Extragalactic Astronomy and Cosmology.$^1$ In the 2015 edition, the relevant section for Galactic microlensing is 2.5 (page 77), and the equations defining the microlensing model lightcurve are 2.92 and 2.93. You don't actually need to read all this, but it can be nice to get some intuition about what's underneath the data.
A source's flux as a function of time, as enhanced by a microlensing event, is given by
$F(t) = F_0 \frac{y(t)^2 + 2}{y(t)\sqrt{y(t)^2+4}}$,
where
$y(t) = \sqrt{p^2 + \left( \frac{t-t_\mathrm{max}}{t_\mathrm{E}} \right)^2}$.
The parameters can be broadly interpreted as follows:
- $F_0$ is the flux in the absence of microlensing;
- $p$ is the impact parameter (in projection) of the lens as is passes in front of the star, in units of its Einstein radius;
- $t_\mathrm{max}$ is the time of maximum magnification;
- $t_\mathrm{E}$ sets the width of the enhancement in the lightcurve.
In practice, you'll also need the transformation between flux and magnitude, given above. For convenience, let's parameterize the normalization of the model lightcurve in magnitudes rather than flux, transforming $F(t)$ to $I(t)$ using the conversion above (with $I$ rather than $m$). We'll have $I_0$ rather than $F_0$ as a normalization parameter; this way, all of the "ref" quantities in the magnitude definition are absorbed into this new parameter and we won't have to worry about them explicitly. With that substitution, the model parameters are $I_0$, $p$, $t_\mathrm{max}$ and $t_\mathrm{E}$.
paramnames = ['I0', 'p', 'tmax', 'tE']
param_labels = [r'$I_0$', r'$p$', r'$t_{max}$', r'$t_E$']
Using the equations above, implement a function predicting the $I$-band magnitude for a microlensing event as a function of $t$ given $I_0$, $p$, $t_\mathrm{max}$ and $t_\mathrm{E}$.
def model_I(t, I0, p, tmax, tE):
"""
Return the model lightcurve in magnitude units, I(t), where t can be an array.
"""
# YOUR CODE HERE
raise NotImplementedError()
Most of the parameters enter the model in an easily interpretable way. $I_0$ sets the constant level of the unlensed lightcurve, $t_\mathrm{max}$ translates the microlensing event in time, and $t_\mathrm{E}$ determines how long the event lasts. $p$ is a little less straightforward, so it helps to plot a few different values:
plt.rcParams['figure.figsize'] = (6.0, 4.0)
plt.xlabel(r'$(t-t_\mathrm{max})/t_\mathrm{E}$');
plt.ylabel(r'$I-I_0$');
plt.gca().invert_yaxis();
tgrid = np.linspace(-3.0, 3.0, 1000)
plt.plot(tgrid, model_I(tgrid, I0=0.0, p=0.1, tmax=0.0, tE=1.0), label='p=0.1');
plt.plot(tgrid, model_I(tgrid, I0=0.0, p=0.5, tmax=0.0, tE=1.0), label='p=0.5');
plt.plot(tgrid, model_I(tgrid, I0=0.0, p=1.0, tmax=0.0, tE=1.0), label='p=1.0');
plt.plot(tgrid, model_I(tgrid, I0=0.0, p=2.0, tmax=0.0, tE=1.0), label='p=2.0');
plt.plot(tgrid, model_I(tgrid, I0=0.0, p=10.0, tmax=0.0, tE=1.0), label='p=10.0');
plt.legend();
Remember that $p$ is proportional to the impact parameter, so smaller $p$ means that the lens passes closer to the star, and hence causes more magnification.
Now that the domain-specific calculations that we'll need are in hand, let's turn to specifying the generative model for these data. Lacking any better information, we'll assume that the sampling distributions for the magnitude measurements (the "magnitude" column) are Gaussian and independent, with means given by the model $I(t)$ and standard deviations given by the "magnitude error" column, and that the time stamps are exact. As usual, we will discuss and collectively decide on priors for the parameters in class. This includes prior probabilities for whether or not there is a microlensing event in the data, since we will do model selection to decide between these possibilities. (As mentioned above, this is a little silly because the OGLE pipeline has already decided the lightcurve has a probable even in it. Nevertheless, we will decide on prior probabilities and work through the exercise.)
Draw the PGM and write out the generative model here:
Space for your generative model
For simplicity, we will want independent prior distributions for each parameter - this is typical anyway, but it especially affects the implementation in this case. Below, specify the priors using scipy.stats distribution objects, or something with equivalent functionality:
#priors = {'I0':...,
# 'p':...,
# 'tmax':...,
# 'tE':...}
# YOUR CODE HERE
raise NotImplementedError()
Finally, the prior probability of a microlensing vs constant model:
# P_microlens = ...
# YOUR CODE HERE
raise NotImplementedError()
P_constant = 1.0 - P_microlens
Fit the microlensing model using standard MCMC¶
The first thing we'll do is fit the microlensing model using methods you're already familiar with, to establish some results that we're confident in.
For both of the methods we'll use in this notebook, we will need a log-likelihood function defined in the usual way. For convenience, given the packages we'll be using, make it a function of a parameter array (in the order I0, p, tmax, tE), rather than with separate, explicit arguments, as we usually do. Remember that we will be computing the evidence, so we want all the normalizing factors correctly included in the sampling and prior distributions.
def log_like(params):
# params is a 1D array of values, whose order is given by paramnames
# YOUR CODE HERE
raise NotImplementedError()
Let's check that this gives us a finite answer for a bad (but not absurd) guess at the parameter values.
guess = [np.mean(data['I']), 1.0, np.mean(data['t']), 100.]
print(log_like(guess))
assert(np.isfinite(log_like(guess)))
Here is our usual log-posterior function, using your definition of the priors and log-likelihood:
def log_posterior(pvec):
'''
Our usual log-posterior function, able to take a vector argument to satisfy emcee
'''
lnp = 0.0
for i,p in enumerate(paramnames):
lnp += priors[p].logpdf(pvec[i])
if lnp != -np.inf:
lnp += log_like(pvec)
return lnp
We'll be using emcee, which will work much better if we start it out near the posterior maximum. Define a parameter vector, start, that looks like a decent fit - it does not need to be perfect. You can use the commented code below to maximize the log-posterior using scipy.optimize.minimize, or just change values by hand until the curve in the figure below looks broadly reasonable. In the former case, you might still need to adjust the minimizer's starting point (guess) to get it to find the best fit.
# start = ...
# or, e.g.
# def objective(pvec):
# return -log_posterior(pvec)
# guess = ...
# opt = minimize(objective, guess, method='Nelder-Mead') # (I used Nelder-Mead because I was too lazy to encode the prior boundaries on the parameters)
# print(opt)
# assert opt.success
# start = opt.x
# YOUR CODE HERE
raise NotImplementedError()
plt.rcParams['figure.figsize'] = (20.0, 4.0)
plt.errorbar(data['t'], data['I'], yerr=data['Ierr'], fmt='.', zorder=0);
tgrid = np.linspace(data['t'].min(), data['t'].max(), 1000)
plt.plot(tgrid, model_I(tgrid, *start));
plt.xlabel('HJD - '+str(data['t0']));
plt.ylabel('I magnitude');
plt.gca().invert_yaxis();
From here, the code to actually perform the MCMC is given. As always, you are responsible for tweaking things and/or adjusting the burn-in length etc. as needed. Note that I had to set the starting ensemble to be quite tight in parameter space to make this work (you can adjust this if necessary), which suggests that you may have trouble if the starting guess is not good enough.
npars = len(paramnames)
nwalkers = 2 * npars
esampler = emcee.EnsembleSampler(nwalkers, npars, log_posterior)
estart = np.array([np.array(start)*(1.0 + 0.001*np.random.randn(npars)) for j in range(nwalkers)])
%%time
esampler.run_mcmc(estart, 5000); # run for longer if you want/need
Don't forget the usual diagnostics!
plt.rcParams['figure.figsize'] = (16.0, 3.0*npars)
fig, ax = plt.subplots(npars, 1);
cr.plot_traces(esampler.chain[:min(8,nwalkers),:,:], ax, labels=param_labels);
burn = 500 # adjust as needed
echain = esampler.chain[:,burn:,:]
R = cr.GelmanRubinR(echain)
print(R)
assert R.max() < 1.1
neff = cr.effective_samples(echain, maxlag=750, throw=True)
print(neff)
assert neff.min() > 300 # this is fewer than we would normally like, but we only want these results to compare to nested sampling
We may as well have a look at the posterior, although we'll forgo computing credible intervals:
echain = np.concatenate(echain, axis=0)
plotGTC(echain, paramNames=param_labels, figureSize=6, customLabelFont={'size':10}, customTickFont={'size':10});
Fit the microlensing model using nested sampling¶
Now that we have an estimate of the posterior from a familiar, albeit not foolproof method, let's see how results from nested sampling compare. Recall that nested sampling is not MCMC, but it will provide what are effectively samples from the posterior, as well as an estimate of the evidence.
Rather than a log-posterior function, we will need to provide the sampler with a log-likelihood function (already done!) and a function that evaluates the quantiles of the prior distributions. This is why we particularly wanted the priors to be independent; one can do this with non-independent priors, but the implementation becomes more complicated.
To be more explicit, we need to write a function that, for each parameter, transforms a number between 0 and 1 to the corresponding quantile of the parameter's prior distribution. (Recall that the quantile function is the inverse of the cumulative distribution function, so it maps cumulative probability onto parameter values.) If your priors dictionary consists of scipy.stats distribution objects, the ppf method is your friend here.
def ptform(u):
'''
Input: a vector in the unit cube, 0 <= u[i] <= 1.
Output: a vector in our parameter space, output[i] = quantile_i(u[i]).
'''
# YOUR CODE HERE
raise NotImplementedError()
The lines below should respectively print the 25th, 50th and 75th percentiles of each parameter's prior, in order:
print(ptform([0.25]*len(paramnames)))
print(ptform([0.5]*len(paramnames)))
print(ptform([0.75]*len(paramnames)))
These cells show the basic setup and running of nested sampling using the dynesty package. This will probably take a few minutes, but pretty soon you should see the dlogz output steadily making its way towards zero.
sampler = dynesty.NestedSampler(log_like, ptform, len(paramnames))
%%time
sampler.run_nested()
The cells below show some standard summaries of the dynesty results, which their documentation says a little more about. ($\ln X$ is the volume of the parameter space allowed by the prior that the algorithm is working in, so you can read increasing $-\ln X$ as the nested sampler making its way to the peak of the posterior.)
results = sampler.results
results.summary()
try:
dynesty.plotting.runplot(results); # this sometimes fails for no identifiable reason; don't worry about it if so
except:
pass
It's not unusual in my limited experience for the evidence plot above to display a flat line, so we plot below the log evidence in the second half of the run. You should be able to see it climbing towards its final value.
plt.rcParams['figure.figsize'] = (12.0, 4.0)
Ndiscard = len(results['logz']) // 2
plt.plot(results['logz'][Ndiscard:]);
plt.xlabel("Iteration - "+str(Ndiscard), fontsize=12);
plt.ylabel("Log Evidence", fontsize=12);
Some more dynesty plots showing how the sampler evolves form exploring the entire prior space towards the posterior maximum.
fig, axes = dyplot.traceplot(results, quantiles=st.norm.cdf([-1,1]), labels=param_labels)
We can extract a set of "equally weighted" samples (i.e. samples we can treat the same way as MCMC samples) using results.samples_equal(). The cell below compares their distribution to the emcee chains. If everything is working well, they should look essentially identical, up to monte carlo noise.
dchain = results.samples_equal()
plotGTC([echain, dchain], paramNames=param_labels, figureSize=6, customLabelFont={'size':10}, customTickFont={'size':10});
Here is an unsophisticated check that nested sampling did, in fact, give us compatible results to MCMC:
assert np.allclose(echain.mean(axis=0), dchain.mean(axis=0), rtol=0.01)
assert np.allclose(echain.std(axis=0), dchain.std(axis=0), rtol=0.1)
Fit a constant model using nested sampling¶
Ok, we are halfway to being able to test whether the Bayesian evidence "detects" a microlensing event in these data. The logical model to compare to is a constant flux from the star, with all the variation attributed to the sampling distribution. Don't worry, this fit will take less time to run.
For our constant model, we have just one free parameter, $I_0$.
paramnames2 = paramnames[:1]
param_labels2 = param_labels[:1]
To make the evidence comparison fair, it makes sense for $I_0$ to have the same prior in both models.
priors2 = {k:priors[k] for k in paramnames2}
Your implementation for the prior quantile function can be completely analogous to the one you wrote earlier, but operating on this 1D parameter space:
def ptform2(u):
'''
Input: a vector in the unit cube, 0 <= u[i] <= 1.
Output: a vector in our parameter space, output[i] = quantile_i(u[i]).
'''
# YOUR CODE HERE
raise NotImplementedError()
We also need a new likelihood function that compares the data to a constant model.
def log_like2(params):
# params is a 1D array of length 1, containing I0
# YOUR CODE HERE
raise NotImplementedError()
For completeness, let's do the same checks of these functions as above.
print(ptform2([0.25]))
print(ptform2([0.5]))
print(ptform2([0.75]))
assert np.isfinite(log_like2(guess[:1]))
Let us patiently run the nested sampler for this model...
sampler2 = dynesty.NestedSampler(log_like2, ptform2, len(paramnames2))
%%time
sampler2.run_nested()
... and gaze upon the results.
results2 = sampler2.results
results2.summary()
try:
dynesty.plotting.runplot(results2);
except:
pass
dyplot.traceplot(results2, quantiles=st.norm.cdf([-1,1]), labels=param_labels2);
Let's extract the final evidence values from the two model fits and compare them:
print("Microlensing model: logz =", results.logz[-1], "+/-", results.logzerr[-1])
print("Constant model: logz =", results2.logz[-1], "+/-", results2.logzerr[-1])
print("Difference in logz =", results.logz[-1]-results2.logz[-1], "+/-", np.sqrt(results.logzerr[-1]**2+results2.logzerr[-1]**2))
Chances are this difference will be an overwhelming evidence ratio when exponentiated. But maybe it isn't for one of the data sets! So let's go ahead and form the posterior ratio for the models (microlensing over constant), not being surprised if it turns out to be numerically infinite.
print("Prior ratio:", P_microlens / P_constant)
print("Evidence ratio:", np.exp(results.logz[-1]-results2.logz[-1]))
print("Posterior ratio:", np.exp(results.logz[-1]-results2.logz[-1]) * P_microlens / P_constant)
Finally, let's compare the posterior mean models with the data. (Normally we would plot multiple parameter samples from each posterior, but in this problem the models are usually so tightly constrained that it's impossible to distinguish the curves.)
dchain2 = results2.samples_equal()
plt.rcParams['figure.figsize'] = (20.0, 4.0)
plt.errorbar(data['t'], data['I'], yerr=data['Ierr'], fmt='.', zorder=0, label='data');
plt.plot(tgrid, model_I(tgrid, *dchain.mean(axis=0)), label='microlensing');
plt.axhline(dchain2.mean(), color='C2', label='constant');
plt.xlabel('HJD - '+str(data['t0']));
plt.ylabel('I magnitude');
plt.gca().invert_yaxis();
plt.legend();
Visually, does the preference or lack of preference for the microlensing model make sense? Does the prior have any bearing on whether we would conclude that there is a microlensing event here?
I_have_answers_to_these_questions = False # change to True when true
# YOUR CODE HERE
raise NotImplementedError()
assert I_have_answers_to_these_questions
Parting thoughts¶
Although the central question of whether lightcurves chosen to contain microlensing events do, in fact, contain microlensing events was a bit contrived, hopefully this tutorial has been useful for confronting the occasional ugliness of real data, and for introducing a package for nested sampling. We have some lingering questions about these data, namely whether the sampling distribution is well described by the "error bars" and whether a constant is acually a good description of the data apart from the lensing event.
Endnotes¶
Note 1¶
From within the Stanford network, it should be possible to download the PDF directly through the link above. From outside, you would need to use the Stanford libraries browser extension detailed on the Stanford library e-resources page (or VPN). Either way, you don't actually need to get the book; the key information is reproduced here.