Tutorial: Fitting a Simple Microlensing Model to an OGLE Lightcurve¶
Here we'll be solving an inference problem using real data, which will be the norm from now on. Specifically, we'll be looking at data from the Optical Gravitational Lensing Experiment (OGLE), which monitors stars in our galaxy in the hopes of detecting gravitational microlensing events that occur when a compact mass (e.g. a fainter star) passes in front of the monitored star.
Data are available through the OGLE Early Warning System. Take a minute to browse around if you'd like; scroll down a bit to the list of recent events, click on one, and have a look. The event summary page will include a plot like this.
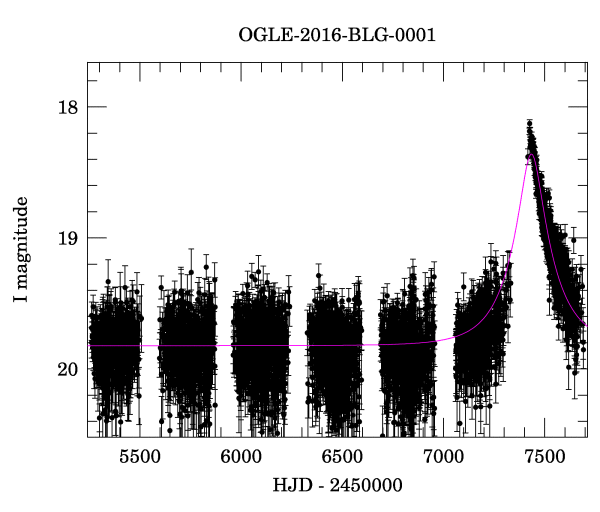 |
You might have fun choosing a lightcurve to fit in this problem (the relevant link is all the way at the bottom of the page for an event, not at the top where it says "click here"), but for the work you turn in you should use this specific event from 2016 so that we know what the results ought to look like. The lightcurve data for this canonical event are saved in tutorials/data/phot.dat.
On a more practical level, in this tutorial you'll be figuring out how to use some pre-packaged sampling software of your choice. You will
- define the generative model for this inference
- use a package of your choice to obtain samples from the posterior
- summarize the posterior distribution and evaluate the goodness of fit, as always