Most probable value and interval¶
This is also sometimes known as "highest posterior density" (HPD).
Quite simply, this convention would report as $\theta_0$ the mode of the marginal posterior. The credible interval is the (possibly multiply connected, i.e. consisting of multiple, disjoint intervals) interval of largest posterior density that contains the specified probability. Consequently, it is also the smallest possible interval containing the target probability.
To help visualize this, the following is one method for determining the HPD interval(s):
- Choose some threshold value of probability density to begin with.
- Integrate the PDF within the interval(s) where it exceeds the threshold.
- Repeat the last step, adjusting the threshold density until the integral (the probability enclosed by the intervals) is what we want it to be.
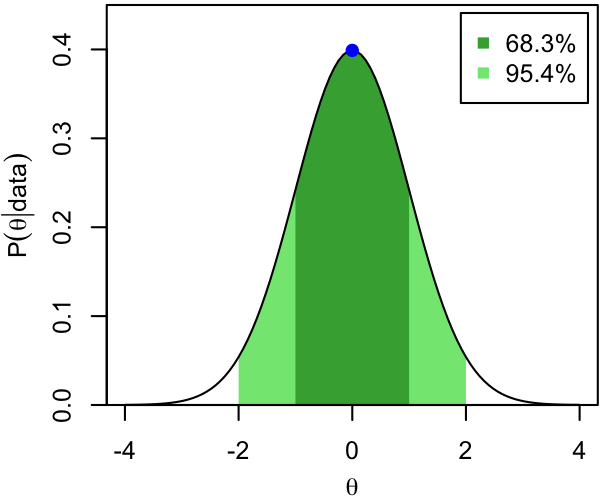
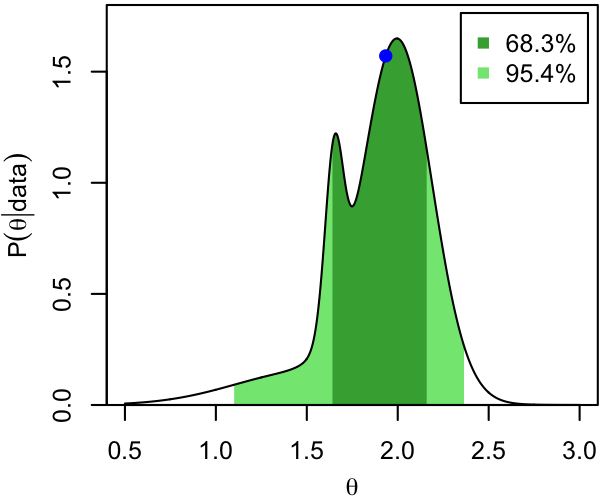
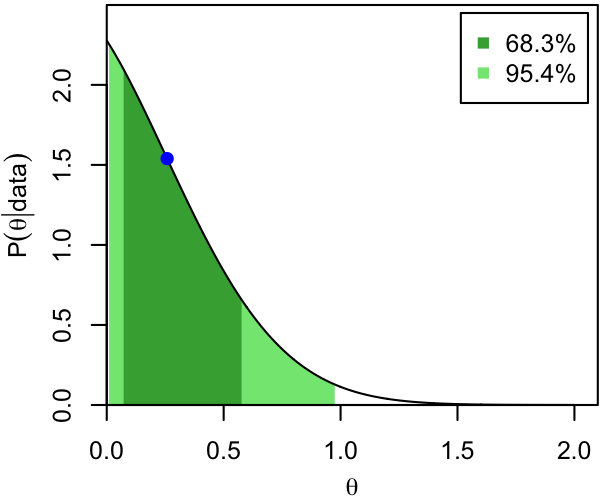
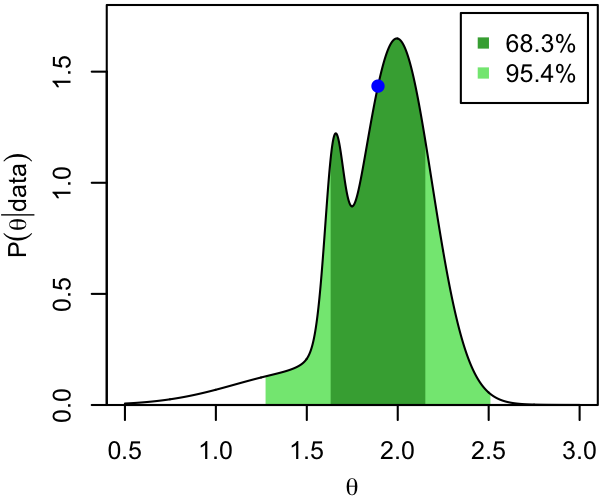
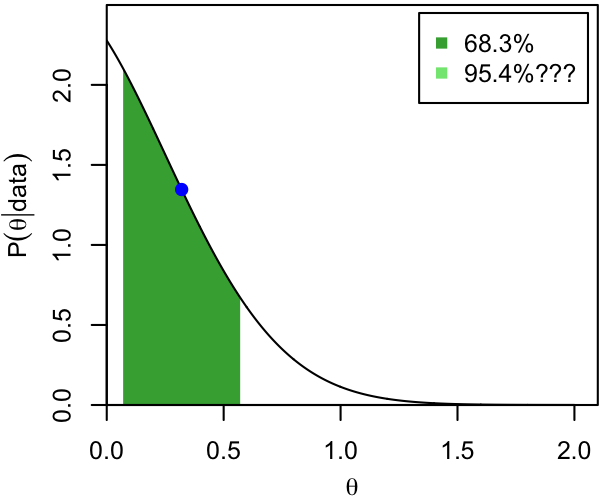
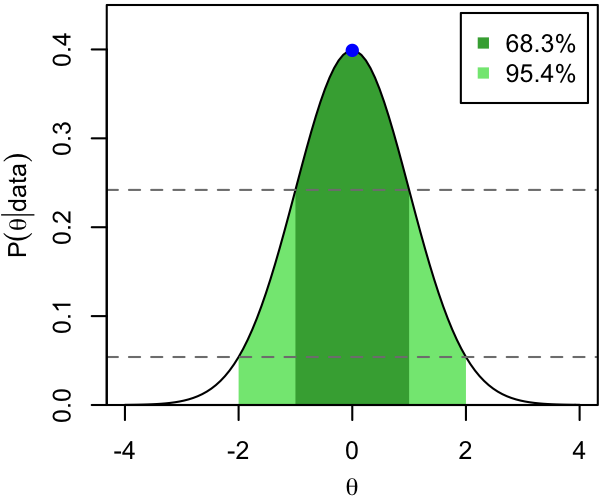
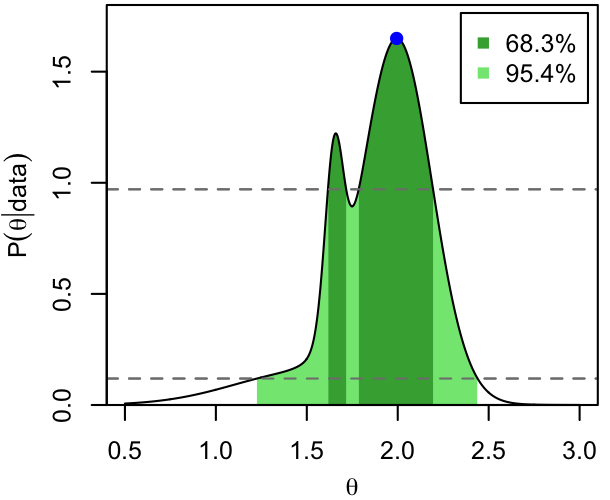
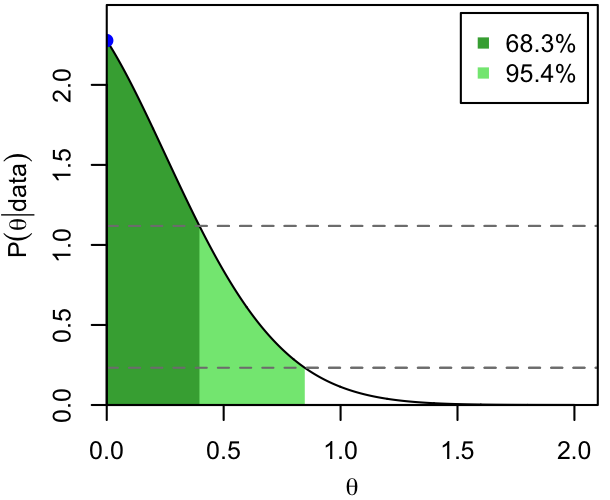
The modes (blue dots) and 68.3% and 95.4% CI's are shown below for 3 (unrelated) PDFs that we'll use as exemplars throughout these notes.
- A standard (mean 0, variance 1) normal distribution, about as simple as they come.
- An asymmetric distribution with multiple modes.
- A very asymmetric distribution, peaking at the edge of the allowed region for its parameter (you might imagine this as providing an "upper limit" for a mass or flux, which cannot be negative by definition).
Dark and light shading show the extent of the two intervals, while the horizontal, dashed lines show the corresponding thresholds in probability density. That is, per the definition and the procedure above, the 68.3% CI consists of all those values of $\theta$ for which $p(\theta|\mathrm{data})$ exceeds the higher dashed line.
 |
 |
 |
Advantages: I would argue that this definition is by far the most intuitive. The nominal value we report is actually the "best" in the sense of most probable given the data, and similarly the interval contains the most probable values. Faced with the statement $\theta = \theta_0 \pm \Delta\theta$, what else would one possibly think?
Similarly, the mode/HPD convention in the right-hand case clearly represents the fact that the posterior is peaked at zero (we would write $\theta=0^{+\Delta \theta}_{-0}$), which the other approaches discussed below would not do.
Finally, this method straightforwardly generalizes to multidimensional credible regions (below), unlike the next option.
Disadvantages: When the CI is multiply connected (the second case, but highly unusual in my limited experience), it's more annoying to describe. Also, when we use Monte Carlo methods to characterize the posterior, we will need to use kernel density estimation (a fancy way to say "smoothing a histogram") to get a smooth function from a finite number of samples; the precise value of the mode and CI limits can be rather sensitive to these details, though generally not at a level that matters (see Significant Digits, above). This means that a human needs to at least look at the distribution to verify that the results are ok (horrors!). I know of exactly one Python package that computes this style of CI correctly, including the multiply connected case, and it's the one I wrote (so, you know, tech support is questionable).